(2주차 - 22.08.02) Python 라이브러리 활용 [데이터 분석] 2
[ 오늘 배운 내용 ]
1. 분석할 수 있는 데이터의 종류 & 분석을 위한 데이터의 구조
2. Numpy
- 넘파이 배열 만들기
- 넘파이 배열 데이터 조회
- 넘파이 배열 연산
3. Pandas
- 데이터프레임
- 데이터프레임 정보 확인
- 데이터프레임 조회
- 데이터프레임 집계
- 데이터프레임 변경
4. matploilib
지난 수업 내용을 간단하게 리뷰하면서 시작했는데 데이터프레임과 시리즈의 차이에 대해 더 자세히 설명을 해 주셨고, 데이터프레임에서 특정 열을 조회하는 방법을 실습해보았다. 특히 칼럼을 지정할 때 ['column']과 [['column']]과 같이 리스트로 한번 더 감싸주냐 마느냐에 따라 조회되는 데이터의 형식이 시리즈와 데이터프레임으로 갈린다는 부분이 신기했다.
그리고 학교에서 인공지능 수업 프로젝트를 진행했을 때 조건으로 데이터프레임을 조회하는 loc과 iloc를 사용해봤었는데
둘의 차이를 명확하게 알 지 못했다. 강사님이 되도록이면 loc 사용하라고 하셔서 그냥 loc만 사용할 것 같다. .loc를 사용할 때 .isin(), between()이라는 정말 좋은 기능을 알게 되었다. 이 메서드를 사용한다면 번거롭게 반복문 조건문으로 데이터프레임에서 데이터를 추출할 필요가 없을 것 같다.
그리고 데이터프레임의 여러 집계함수들에 대해서도 배웠는데 groupby()라는 매우 유용한 메서드를 알게 되었다. ~별~의 집계함수 결과를 알고 싶다면 groupby를 사용하도록 하자. groupby 말고도 한번에 여러 방식의 집계 결과를 보게 해주는 agg()도 기억을 하면 좋을 것 같다.
마지막으로 열 이름 변경, 열 삭제, 열 추가, map(), cut() 등 나중에 프로젝트 진행 시 꼭 필요할 내용들만 액기스로 알아갈 수 있었던 것 같다.
마지막으로는 가볍게 matplotlib 라이브러리로 간단한 시각화 실습을 해 보았는데 이 내용은 어차피 나중 수업에서 다시 다룰 예정이라고 하셔서 잠깐 남은 시간을 활용해서 맛만 보았다.
*사용 데이터 : IBM의 직원 이탈 데이터
-> 강사님의 깃허브 url을 통해 데이터 내려받아 사용했음
1. 데이터프레임 조회
- 데이터프레임(Dataframe) : 2차원 구조
- 시리즈(Series) : 1차원 구조 (데이터프레임에서 칼럼(=정보) 하나를 떼어 낸 것)
# 데이터 읽어오기
path = '데이터 링크'
data = pd.read_csv(path)
# 상위 5개 확인
data.head(5)실행 결과

- 특정 열 조회
# Attrition열 조회 - Series로 조회
data['Attrition']
# Attrition, Age열 조회 - Dataframe으로 조회
data[['Attrition', 'Age' ]]실행결과 (시리즈로 조회)

실행결괴 (데이터프레임으로 조회)
- 시리즈와 데이터프레임 두 가지 형식으로 불러와서 조회할 수 있는데 데이터프레임으로 불러와서 보는 것이 보기는 더 좋은 것 같다.
- 하나의 칼럼만 불러와도 []대괄호로 한 번 더 감싸주면 시리즈가 아닌 데이터프레임으로 불러온다.
- 여러 칼럼을 조회할 때는 칼럼 이름들을 리스트에 담아서 데이터프레임 형식으로 불러온다.
- 조건으로 조회
df.loc[조건] 형태로 조건을 지정해 조건에 만족하는 데이터만 조회할 수 있다.
# 단일 조건 조회
# DistanceFromHome 열 값이 10 보다 큰 행 조회
data.loc[data['DistanceFromHome'] > 10]DistanceFromeHome 열 값이 10보다 큰 행 조회
- 여러 조건으로 조회 - &(and), |(or) 연산자 사용
각 조건은 소괄호()로 묶어줘야 한다.
# and로 여러 조건 연결 (교집합)
data.loc[(data['DistanceFromHome'] > 10) & (data['JobSatisfaction'] == 4)]
# or 조건 : | (합집합)
data.loc[(data['DistanceFromHome'] > 10) | (data['JobSatisfaction'] == 4)]'DistancaFromHome'이 10보다 크고 'JobSatisfaction'이 4인 데이터 조회 (&연산자 실행 결과)

- .isin()과 .between() 메소드 사용
.isin( [ 값1, 값2, ..., 값n ] ) : 값1 또는 값2 또는 ... 값n인 데이터만 조회
.between(값1, 값2) : 값1~값2까지 범위 안의 데이터만 조회
# 값 나열 -> Jobsatisfaction이 1 또는 4인 데이터만
data.loc[data['JobSatisfaction'].isin([1,4])]
# 범위 지정 -> Age가 25~30인 데이터만
data.loc[data['Age'].between(25, 30)]
- 조건을 만족하는 행의 일부 열만 조회
df.loc[ 조건, [ '열 이름1', '열 이름2', ... ] ] 형태로 조회할 열을 리스트로 지정하면 2차원의 데이터프레임 형태로 조회 가능
# 칼럼 이름을 시리즈(1차원)으로 조회
data.loc[data['MonthlyIncome'] >= 10000, 'Age']
# 칼럼 이름을 데이터프레임(2치원)으로 조회
data.loc[data['MonthlyIncome'] >= 10000, ['Age']]
# 위 코드와 같은 결과 (실행 시간이 조금 더 길긴 한데 크게 차이는 없는듯)
data.loc[data['MonthlyIncome'] >= 10000][['Age']]# 조건에 맞는 여러 열 조회
data.loc[data['MonthlyIncome'] >= 10000, ['Age', 'MaritalStatus', 'TotalWorkingYears']]실행 결과
2. 데이터프레임 집계
여러 데이터프레임 집계 관련 메소드
- 합 : sum()
- 평균 : mean()
- 최댓값 : max()
- 최솟값 : min()
- 개수 : count()
- 중간값 : median()
# MonthlyIncome 합계
data['MonthlyIncome'].sum()
# MonthlyIncome, TotalWorkingYears 각각의 평균
data[['MonthlyIncome', 'TotalWorkingYears']].mean()
- ~별 ~의 집계 구하기
df.groupby( by='열1', as_index= )[ '열2' ].집계함수
- '열1' 별 '열2'를 집계함수로 집계해줌
- as_index는 '열1'의 정보를 인덱스로 할 지 결정 (False로 설정 시 행 번호를 기반으로 한 정수 값이 인덱스로 설정)
# MaritalStatus 별 Age의 평균 --> 결과 데이터프레임으로
data.groupby('MaritalStatus', as_index=False)[['Age']].mean()실행 결과
- 여러 열에 대한 집계 수행
data.groupby('MaritalStatus', as_index=False)[['Age','MonthlyIncome']].mean()
- 집계 기준 열을 여러개로 설정
# 'MaritalStatus', 'Gender'별 나머지 열들 평균 조회
data.groupby(['MaritalStatus', 'Gender'], as_index=False)[['Age','MonthlyIncome']].mean()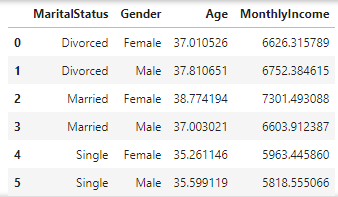
- 여러 집계 함수를 한꺼번에 집계
df.groupby().agg( [ '함수1', '함수2', ... ] )
- as_index는 적용되지 않는다. 무조건 집계 기준 열이 인덱스 열이 됨.
- by옵션 사용 (생략해서 사용 가능 - 아래 코드에선 원래 by = 'MartialStatus')
data.groupby('MaritalStatus', as_index=False)[['MonthlyIncome']].agg(['min','max','mean'])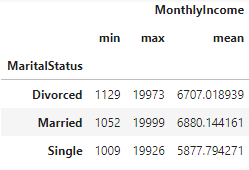
- 여러 열에 대해 각 열마다 다른 집계 수행
agg() 안에 리스트[] 말고 {key : value}의 딕셔너리 형태로 지정해준다.
# [ 각 열마다 다른 집계를 한번에 수행하기 ]
# 성별(Gender) 별 ==> 나이(Age) : 평균 / 월급(MonthlyIncome) : 최대값
data.groupby(by='Gender').agg({'Age' : 'mean', 'MonthlyIncome' : 'max'})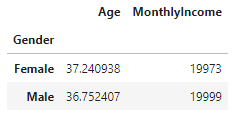
3. 데이터프레임 변경
- 열 이름 변경
- columns의 속성을 변경해서 모든 열의 이름을 변경 가능
- rename()메소드를 사용하여 지정한 열의 이름 변경 가능 (inplace=True 옵션을 주어야 실제 적용)
# 모든 열 이름 변경 - 모든 칼럼이 순서대로 들어가야 함
data.columns = ['Attr','Age','Dist','EmpNo','Gen','JobSat','Marital','M_Income', 'OT', 'PctSalHike', 'TotWY']
# rename() 함수로 열 이름 변경
data.rename(columns={'DistanceFromHome' : 'Distance',
'EmployeeNumber' : 'EmpNo',
'JobSatisfaction' : 'JobSat',
'MonthlyIncome' : 'M_Income',
'PercentSalaryHike' : 'PctSalHike',
'TotalWorkingYears' : 'TotWY'}, inplace=True)
- 열 추가
- 없는 열을 변경하면 맨 뒤에 그 열이 추가된다.
올해 급여(M_Income) 와 급여 인상률(PctSalHike)을 조합하여 계산한 작년 급여(Income_LY) 칼럼을 추가
# Income_LY 열 추가
data['Income_LY'] = data['M_Income'] / (1+data['PctSalHike']/100 )
data['Income_LY'] = round(data['Income_LY']) #round는 반올림 함수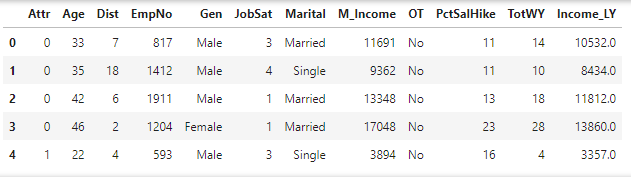
- 열 삭제
- drop() 메소드를 사용해 열 삭제가 가능하다.
- axis=0 : 행 삭제
- axis=1 : 열 삭제
- inplace=True 옵션 지정해줘야 실제로 삭제 반영
# Income_LY 열 삭제
data.drop('Income_LY', axis=1, inplace=True)
- 삭제할 열을 리스트 형태로 전달해 한 번에 여러 열 제거 가능
# 열 두 개 삭제
data.drop(['EmpNo','OT'], axis=1, inplace=True)
- 범주형 값을 다른 값으로 변경 - map() 메소드
- map() 메소드를 사용하면 범주형 값을 다른 값으로 쉽게 변경 할 수 있다.
Gen 변수의 Male, Female을 각각 숫자 1, 0으로 변경
# Male -> 1, Female -> 0
data['Gen'] = data['Gen'].map({'Male': 1, 'Female': 0})
# 확인
data.head()
- 크기를 기준으로 범위를 나누어 등급을 지정하기 - cut() 메소드
- cut() 메소드를 사용하여 값의 크기로 지정한 개수의 범위로 나누어 줄 수 있다.
# 수치의 최소~최대값을 3등분
pd.cut(data['M_Income'], 3)
# (10,20] : 10초과 20이하- M_Income 값을 최소~최대값까지 3등분을 하여 나누어 줌
- 기본적으로 나누어진 범위는 ( , ]의 형태이다. <--> right=False 옵션을 주면 [ , )의 범위가 된다.

# 범위를 3등분해서 등급 구하기
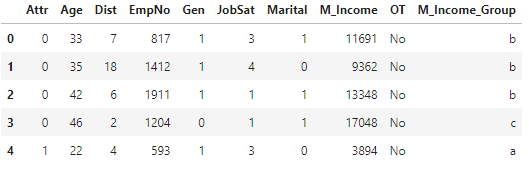
data['M_Income_Group'] = pd.cut(data['M_Income'], 3, labels=['a', 'b', 'c'] )
# 확인
data.head()M_Income을 3 구간으로 나누어서 각 구간에 'a', 'b', 'c'의 이름을 붙인 열을 새로 만들어준다.
- 나눠진 범위 확인
# 범위 확인
data.groupby('M_Income_Group', as_index = False)['M_Income'].agg(['min', 'max'])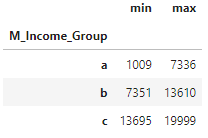
- bins 옵션을 사용하여 범위 나누기
아래 범위에 따른 값을 갖는 M_Income_Group2 열을 추가해주고 범위를 확인해보았다.
- 10000 이하 → 'a'
- 10000 초과 15000 이하 → 'b'
- 15000 초과 → 'c'
# 등급 구하기
bin = [0, 10000, 15000, np.inf] # 구간에 해당하는 값들을 넣어줌 a, b, c로 (0, 10000, 15000~)을 3등분
data['M_Income_Group2'] = pd.cut(data['M_Income'], bins=bin, labels=['a', 'b', 'c'])
# 범위 확인
data.groupby('M_Income_Group2', as_index = False)['M_Income'].agg(['min', 'max'])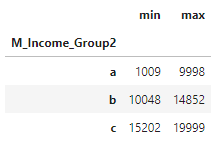
4. 데이터 시각화 라이브러리 matplotlib
matplotlib.pyplot
- 파이썬에서 그래프를 그릴 때 기본이 되는 라이브러리
- 데이터 분석을 위한 다양한 차트들을 제공한다.
- 라이브러리 로딩
import matplotlib.pyplot as plt
- 차트 그리기
plt.plot( 'x축 정보', 'y축 정보', data = data )
- 데이터프레임의 칼럼 이름을 주어서 x축과 y축으로 사용할 변수를 지정해줄 수 있다.
- 칼럼 이름을 하나만 줄 경우 y축 정보로 사용된다.
- 화면에 보여주기
plt.show()
예시코드
# 날짜 축으로 item1에 대해 라인차트를 그려봅시다. - x축 : 'date' / y축 : 'item1'
plt.plot('date', 'item1', data = data)
plt.show()실행해서 그래프를 그려보면 x축의 값이 너무 길어서 지저분한 것을 볼 수 있다.
- x축의 값을 회전시키기
xticks() 메서드를 사용해서 x축의 값을 회전시킬 수 있다.
plt.plot(data['date'], data['item1']) # 위 코드와 동일한 코드임
plt.xticks(rotation=45)
plt.show()실행해보면 훨씬 보기 좋아진 그래프를 확인할 수 있다.
요약 정리
[ 판다스 데이터프레임 ]
* 조건 조회
df.loc[행조건, 열조건]
행 조건 -> .isin(), .between()
열 조건 -> '열' : 시리즈 / ['열'] : 데이터프레임
* 데이터프레임 집계 관련 메소드
sum(), mean(), max(), min(), count(), median()
* ~별 ~의 집계함수 결과
df.groupby(by='열1', as_index= )['열2'].집계함수
'열1' 별 열2를 집계함수로 집계한 결과 (as_index : '열1'을 인덱스로 할 지)
* 여러 집계 함수를 한꺼번에 집계
df.groupby().agg( [ '함수1', '함수2', ... ] )
* 열 이름 변경
df.rename( columns={ '바꿀 열' : '바꿀 이름' }, inplace=True )
* 열 추가
없는 열을 변경하면 맨 뒤에 추가된다.
* 열 삭제
df.drop( '삭제할 열', axis= , inplace=True )
axis = 0 행 삭제
axis = 1 열 삭제
* 범주형 값을 다른 값으로 변경
map()
* 크기를 기준으로 범위를 나누어 등급 지정하기
pd.cut( 대상 칼럼, bins=bin, labels=[ 'a', 'b', 'c', 'd' ], right=False )
bin은 범위를 나누는 기준이 될 값들의 리스트
[ matplotlib 라이브러리 ]
* 그래프 그리기
plt.plot( 'x축 정보', 'y축 정보', data = data )
* x축 값 회전시키기
plt.xticks(rotation=45)
* 화면에 보여주기
plt.show()