
[ 오늘 배운 내용 ]
1. 분석할 수 있는 데이터의 종류 & 분석을 위한 데이터의 구조
2. Numpy
- 넘파이 배열 만들기
- 넘파이 배열 데이터 조회
- 넘파이 배열 연산
3. Pandas
- 데이터프레임
- 데이터프레임 정보 확인
- 데이터프레임 조회
- 데이터프레임 집계
- 데이터프레임 변경
4. matploilib
되게 친숙하게 수업해주시는 강사님이 이번 강의를 진행해주셨다. 덕분에 편한 분위기에서 수업을 들을 수 있었던 것 같다.
이번 수업에서는 데이터 분석에서 가장 많이 쓰이는 파이썬 라이브러리인 Numpy와 pandas, 그리고 matplotlib 라이브러리에 대해 배웠다.
시작하기에 앞서 데이터 분석 프로세스의 가장 기본적인 그림이라고 하시는 CRISP-DM 구조를 보고 나서 범주형과 수치형 데이터의 차이, 기본적인 행,열 구조의 2차원 데이터에서 각 행과 열은 무엇을 의미하는지에 대해 간단한 설명을 해 주셨다.
먼저 넘파이 라이브러리를 사용하여 넘파이의 여러 기능을 직접 사용해보았다. 넘파이에서 Axis, Rank, Shape 각 용어가 무엇을 나타내는지와 넘파이 배열을 만들고 여러 정보를 확인하는 메서드와 형변환 메서드 등을 사용해보았고, 넘파이 배열의 데이터를 여러 방식으로 조회해보았다.
넘파이 배열의 기본적인 연산과 일반 연산과의 차이점, sum(), mean(), std()와 같은 다양한 집계 함수를 배웠다. 그리고 특히 기억에 남는건 np.where함수였는데 조건에 따라 다른 값으로 넘파이 배열을 바꿔줄 수 있는 유용한 함수였던 것 같다.
그 밖에 np.argmax, np.argmin과 axis=0, axis=1이 무엇을 의미하는지 등에 대해 배우고 판다스로 넘어갔다.
판다스 라이브러리에서 사용되는 자료구조인 데이터프레임과 시리즈에 대해 배웠고, csv파일을 read_csv() 사용하여 데이터프레임으로 읽어온 뒤 여러 정보 확인 메서드를 사용해보았다. 그리고 데이터를 정렬해주는 sort_values()메서드와 고유값을 확인해주는 unique(), value_counts() 등 여러 유용한 메서드를 사용해보았다.
이런 라이브러리들은 특히 각 메서드에서 필요한 옵션들이 많은 것 같은데 이 옵션들을 많이 알아두면 나중에 많은 도움이 될 것 같았다. 참고로 나는 주피터랩에서 실습을 했는데 여기서만 사용할 수 있는 건진 모르겠지만 메서드를 입력하고 shift + tab을 누르면 함수에서 사용하는 여러 옵션에 대한 정보를 볼 수 있어서 정말 유용했다.
1. 분석할 수 있는 데이터
우리가 분석할 수 있는 데이터는 범주형 데이터와 수치형 데이터로 나뉜다.
[ 범주형 데이터 (질적 데이터, 정성적 데이터) ]
: 집단(그룹)으로 묶을 수 있는 데이터
- 명목형 데이터
ex) 성별, 시/도, 흡연여부, 음주여부
- 순서형 데이터
ex) 연령대 매출등급
[ 수치형 데이터 (양적 데이터, 정량적 데이터) ]
: 숫자(수치)로 나타내는 데이터
- 이산형 데이터
ex) 판매량, 매출액, 나이
- 연속형 데이터
ex) 온도, 몸무게
분석할 수 있는 데이터는 아래와 같이 기본적으로 2차원의 테이블 형대로 표현된다.
아래의 표는 여러 정보에 따른 아이스크림의 판매량을 예측하기 위한 데이터의 예시이다.
| 날짜 | 비 | 습도 | 기온 | 요일 | 휴일 | 판매량 |
| 2021.05.01 | N | 34 | 16 | 토 | Y | 4,560 |
| 2021.05.02 | Y | 50 | 26 | 일 | Y | 4,290 |
| 2021.05.03 | N | 42 | 12 | 월 | N | 2,340 |
| ... | ... | ... | ... | ... | ... | ... |
여기서 각 열을 구성하는 날짜, 비, 습도, 기온, 요일, 휴일은 Feature(요인)라고 하며 예측하려는 판매량은 Target(결과)라고 한다.
각 행은 하나의 단위 데이터를 나타낸다.
각 행과 열을 가리키는 여러 용어가 있는데,
일반적으로
- 열 -> 변수, 요인, Features, X 등으로 불리고
- 행 -> 분석단위, Target, y 등으로 불린다.
데이터 분석을 위한 데이터 구조(자료형)을 제공하는 파이썬의 라이브러리로서 가장 많이 사용되는 라이브러리는 Numpy(넘파이)와 pandas(판다스)가 있다 .
2. 데이터 분석을 위한 라이브러리 Numpy
Numpy
넘파이는 빠른 수치 계산 및 대량의 데이터를 처리하기 좋은 파이썬 라이브러리이다.
- 넘파이 임포트
import numpy as np
[ 용어 정리 ]
- Axis : 배열의 각 축
- Rank : 축의 개수(차원)
- Shape : 축의 길이 (데이터의 개수)
| 1 | 3 | 2 | 7 |
| 3 | 2 | 9 | 1 |
| 4 | 6 | 8 | 1 |
위와 같은 형식의 데이터의 경우에는
Rank : 2개 (2차원)
shape : (3, 4) 이며
axis = 0 축은 각 열을 나타내는 ↓ 방향이고
axis = 1 축은 각 행을 나타내는 → 방향이다.
- 넘파이 배열 생성
# 1차원 리스트
a1 = [1, 2, 3, 4, 5]
# 배열로 변환
b1 = np.array(a1)- 넘파이 배열 정보 확인
# 배열 차원 확인
a.ndim
# 배열 형태 확인
a.shape
# 요소 자료형 확인
a.dtype실행결과
1
(5, )
int32
shape로 형태 확인 시
- 1차원 배열의 경우 (5, ) -> 값 5개
- 2차원 배열의 경우 (3, 5) -> 5개짜리 값이 3개
- 3차원 배열의 경우 (2, 3, 5) -> 3x5개짜리 값이 2개
와 같은 식으로 표현된다.
- reshape명령어를 사용하여 넘파이 배열의 형태를 변경
# (3, 2) 형태의 2차원 배열로 Reshape
b = a.reshape(3, 2)
- (m, -1) 또는 (-1, n) 처럼 행 또는 열 크기 한쪽만 지정하여 reshape
# a를 3행으로 된 배열로 변환
a.reshape(3, -1)
# a를 2열로 된 배열로 변환
a.reshape(-1, 2)
- 배열의 데이터 조회 방법
# 요소 조회 - 0행1열 요소
a[0,1]
# 행 조회 - 1,2번째 행 조회
a[[0,1], : ]
a[[0,1]] # 행 조회는 : 생략 가능
# 열 조회 - 1,2번째 열 조회
a[ : , [0,1]]
# 행, 열 조회
# 단일 스칼라 값으로 조회
a[1,1]
# 2번째 행 2번째 열의 요소 조회 (1차원 값으로)
a[[1], [1]]
# (0,0), (1,1), (2,0) 위치의 요소 조회
# a[[행번호],[열번호]]
a[[0,1,2], [0,1,0]]
- 조건 조회
score = np.array([[78, 91, 84, 89, 93, 65],
[82, 87, 96, 79, 91, 73]])
print(score[score < 80])실행 결과
[78 65 79 73]
- 넘파이 배열 끼리의 연산
같은 shape의 넘파이 배열끼리 사칙연산(+, -, *, /, ** 등)을 할 때에는 같은 위치의 원소끼리 계산된다. (element-wise)
- 배열 집계
# 전체 합 집계
np.sum(a)
# 열 기준 집계 (열 별)
np.sum(a, axis=0)
# 행 기준 집계 (행 별)
np.sum(a, axis=1)- np.sum() : 합
- np.mean() : 평균
- np.std() : 표준편차
등 사용 가능
- np.where를 사용하여 조건에 따라 다른 값 지정하기
# np.where(조건문, 참일때 값, 거짓일때 값)
# 배열 a에서 3보다 큰 원소의 자리에 1, 아닌 자리에 0
np.where(a>3, 1, 0)
- 가장 큰(작은) 값의 인덱스 반환 np.argmax, np.argmin
# 전체에서 최대값의 인덱스
np.argmax(a)
# 열 기준 최대값의 인덱스
np.argmax(a, axis=0)
# 행 기준 최대값의 인덱스
np.argmax(a, axis=1)
3. 데이터 분석을 위한 라이브러리 Pandas
Dataframe(데이터프레임)
- 판다스에서 사용하는 데이터 구조로 데이터 분석에서 가장 중요한 데이터 구조이다.
- 관계형DB의 테이블 또는 엑셀시트와 같은 2차원 구조의 형태
- 변수들의 집합 -> 각 열을 변수라고 부름
- 열(column) -> 정보, 변수(feature, target)
- 행(row) -> 분석 단위, 관측치, 샘플
Series(시리즈)
- 하나의 정보에 대한 데이터들의 집합
- 데이터프레임에서 하나의 열을 떼어낸 것 (1차원)
- 판다스 라이브러리 불러오기
import pandas as pd
- csv 데이터 읽어오기
# 데이터 읽어오기
path = '데이터 경로'
data = pd.read_csv(path)
# 상위 10행만 확인
data.head(10)head()메소드를 통해 앞쪽의 데이터를 확인 가능한데 개수를 따로 지정해주지 않으면 기본적으로 5개의 데이터를 확인한다.
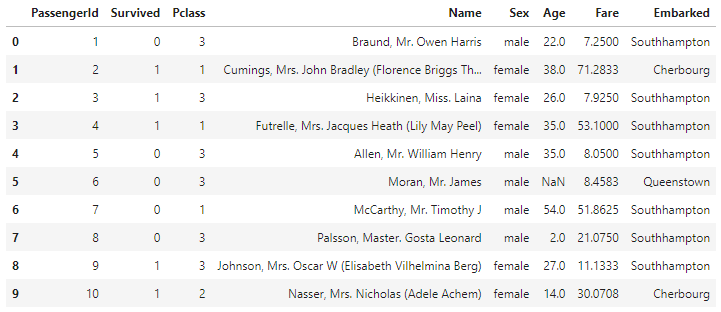
- 데이터프레임의 여러 메소드
# 앞쪽 데이터 확인
df.head()
#뒤쪽 데이터 확인
df.tail()
# 데이터프레임 모양 확인 (행수,열수) 형태
df.shape
# 인덱스 정보 확인
df.index
# 값 확인 (값만 떼어내서 넘파이 배열로 반환)
df.values
# 열 정보 확인 (칼럼 이름 반환)
df.columns()
df.columns.values
list(df)
# 열별 자료형 확인
df.types
- df.types 실행 예시
Attrition int64
Age int64
DistanceFromHome int64
EmployeeNumber int64
Gender object
JobSatisfaction int64
MaritalStatus object
MonthlyIncome int64
OverTime object
PercentSalaryHike int64
TotalWorkingYears int64
dtype: objectobject는 문자열
- 인덱스, 열, 값 개수, 데이터 형식 등 정보 확인
df.info()실행 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1196 entries, 0 to 1195
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Attrition 1196 non-null int64
1 Age 1196 non-null int64
2 DistanceFromHome 1196 non-null int64
3 EmployeeNumber 1196 non-null int64
4 Gender 1196 non-null object
5 JobSatisfaction 1196 non-null int64
6 MaritalStatus 1196 non-null object
7 MonthlyIncome 1196 non-null int64
8 OverTime 1196 non-null object
9 PercentSalaryHike 1196 non-null int64
10 TotalWorkingYears 1196 non-null int64
dtypes: int64(8), object(3)
memory usage: 102.9+ KB
- 기초 통계 정보 확인
df.describe()실행 예시
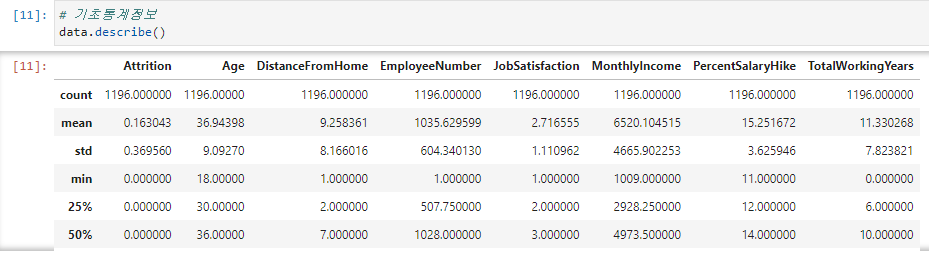
data[['Age', 'MonthlyIncome']].describe() 같은 식으로 일부 열에 대해서만 기초통계정보 확인도 가능하다.
- 데이터프레임 정렬해서 보기
# 인덱스를 기준으로 정렬
df.sort_index(ascending=True)
# 특정 열을 기준으로 정렬
df.sort_values(by='기준 열', ascending=True)sort_values() 실행 예시
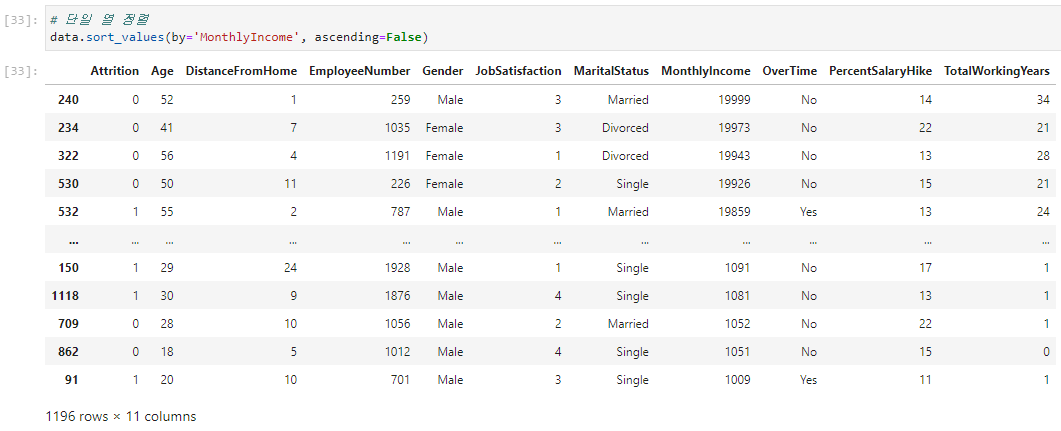
by 옵션으로 정렬의 기준이 될 열을 지정할 수 있고, ascending 옵션을 통해 오름차순(True)과 내림차순(False) 정렬을 선택할 수 있다. 디폴트 값은 True이다.
- 복합 열 정렬
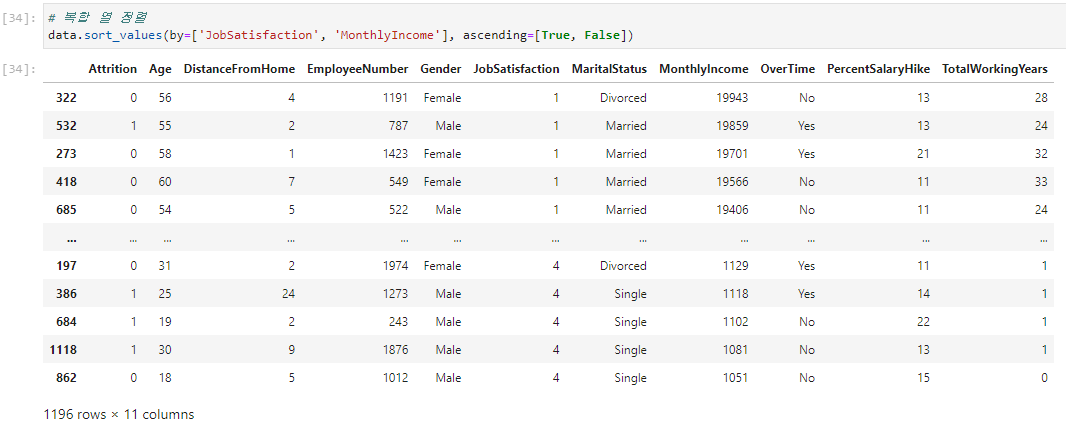
위와 같이 여러 열을 기준으로 정렬이 가능한데 먼저 지정된 열을 기준으로 우선 정렬되고, 같은 값일 시 이어서 지정된 열을 기준으로 정렬된다.
위의 예시는 JobSatisfaction 열을 오름차순(True)으로 먼저 정렬하고, JobSatisfaction이 같은 데이터들은 MonthlyIncome 열의 값을 기준으로 내림차순(False)으로 정렬한다.
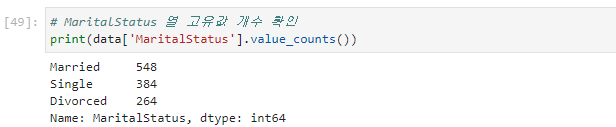
- 범주형 열의 고유값 확인 메소드 unique(), value_counts()
# 고유값 확인
df['범주형 칼럼'].unique()
# 고유값과 그 개수 확인
df['범주형 칼럼'].value_counts()unique() 실행 예시

value_counts() 실행 예시
- 기본 통계 메소드
# MonthlyIncome 열 합계 조회
data['MonthlyIncome'].sum()
# MonthlyIncome 열 최댓값 조회
data['MonthlyIncome'].max()
# 'Age', 'MonthlyIncome' 열 평균값 확인
data[['Age', 'MonthlyIncome']].mean()
# 'Age', 'MonthlyIncome' 열 중앙값 확인
data[['Age', 'MonthlyIncome']].median()
'KT AIVLE School' 카테고리의 다른 글
| (2주차 - 22.08.04) 웹크롤링2 (0) | 2022.08.04 |
|---|---|
| (2주차 - 22.08.03) 웹크롤링 1 (0) | 2022.08.03 |
| (2주차 - 22.08.02) Python 라이브러리 활용 [데이터 분석] 2 (0) | 2022.08.02 |
| (1주차 - 22.07.28~22.07.29) Python 프로그래밍 (0) | 2022.08.01 |
| (1주차 - 22.07.27) IT 프로젝트 관리도구 - Git (0) | 2022.08.01 |