
[ 오늘 배운 내용 ]
1. 웹(Web) 관련 지식 간단 정리
- 웹페이지 종류
- 웹크롤링 절차
2. 네이버 증권 데이터 크롤링 (동적페이지)
- 최근 60일치의 KOSPI, KOSDAQ 데이터 + 원-달러 환율 데이터 크롤링
- copy(), apply, lambda 함수
- 데이터의 상관관계 분석
3. 네이버 파파고 API 사용 실습
오늘부터 3일동안 웹크롤링 수업을 진행하시는 강사님께서 웹 크롤링을 시작하기 전에 웹에 대한 여러 내용들을 알려 주셨다. 서버-클라이언트의 웹 서비스 구조와 URL의 구성요소, 서버와 클라이언트가 Get 또는 Post 방식으로 데이터를 요청하여 주고받는 과정을 그림을 그려가며 설명해주셨다.
그 밖에 인터넷과 OSI 7계층, 쿠키,세션,캐시, HTTP status code 등에 대해서도 설명해주셨다.
간단한 웹 지식들을 습득한 뒤 크롤링 실습에 앞서 정적페이지와 동적페이지에 대해 배웠다. 페이지가 변경될 때 URL이 바뀌는지, 바뀌지 않는지로 나뉘면서 각 페이지 종류마다 요청으로 받는 데이터의 형식도 다르다는 것을 알았다. 정적,동적페이지의 차이점과 url -> request -> dataframe 순으로 데이터를 받고 처리하는 크롤링의 기본적인 과정을 여러번 강조하며 설명해주셔서 기억에 잘 남았다.
가장 먼저 동적페이지인 네이버 증권 사이트에서 KOSPI, KOSDAQ의 데이터와 원-달러 환율 데이터를 받아와서 데이터프레임의 형태로 가공하고, 이 과정을 하나의 함수로 만들어 보았다.
API를 사용하는 것이 아닐 때에는 해당 페이지에서 크롬의 개발자 도구를 통해 네트워크 탭에서 트래픽들을 확인해 주어야 한다. 이 때 받아오는 응답을 확인하고 필요한 데이터가 들어있는 것을 찾으면 해당 요청 url을 사용하면 된다.
함수를 만들 때 Docstring(독스트링)이라는 기능도 알게 되었고, 수집한 3가지 데이터의 상관관계도 피어슨 상관계수를 사용해서 분석해보았다.
추가적으로 copy()를 통해 얕은 복사와 깊은 복사의 차이점을 설명해주셨고, apply와 람다식도 알려주셔서 파이썬을 좀 더 효율적으로 다룰 수 있는 여러 방법을 알 수 있었다.
다음으로는 네이버에서 제공되는 파파고 API를 통해 한글 텍스트를 입력하면 영어로 번역된 결과를 받아오는 실습을 진행하였다. API 사용 시 키를 생성하고 각 웹 애플리케이션의 도큐먼트를 확인해서 API 사용법을 분석하고 params(post요청 시에만)와 headers를 추가해서 요청을 보내는 방법도 경험해보았다.
엑셀 파일을 불러와서 안에 있는 제목 데이터들의 영어 버전 칼럼도 추가해서 저장하는 실습도 해보았다.
웹 (Web)
웹 서비스는 서버-클라이언트 구조로 이루어져있다.
- 서버(Server) : 클라이언트가 데이터를 요청하면 요청에 따라 데이터를 전송
- 클라이언트(Client) : 브라우저를 통해 서버에 데이터를 요청
[ URL (Uniform Resource Locator)의 구조 ]
예시)
http://news.naver.com:80/main/read.nhn?mode=LSD&mid=shm&sid1=105&oid=001&aid=0009847211#da_727145
- http:// ==> 프로토콜(Protocol)
- news ==> 서브 도메인
- naver.com ==> 도메인(Domain)
- 80 ==> 포트(Port)
- /main/ ==> 경로(Path)
- read.nhn ==> 페이지(=파일)
- ?mode=LSD&mid=shm&sid1=105&oid=001&aid=0009847211 ==> 쿼리(query)
- #da_727145 ==> fragment
[ Get & Post ]
서버로 데이터를 요청하는 방식의 한 종류
- Get : URL에 데이터가 포함된다. (데이터가 노출)
- Post : Body에 데이터가 포함된다. (데이터가 숨겨짐)
[ Cookie & Session & Cache ]
Cookie
- 클라이언트(브라우저)에 저장하는 문자열 데이터로 도메인 별로 따로 저장된다.
- 로그인 정보, 내가 봤던 상품 정보 등이 있음 ex) 쿠팡에서 본 물건이 다른 사이트 광고로 쫓아오는 경우
Session
- 서버에 저장하는 연결 정보의 객체 데이터로, 브라우저와 연결 시 Session ID 생성
- 세션ID 를 쿠키에 저장함으로써 로그인 연결이 유지된다.
- 같은 브라우저로 같은 서버에 접속하면 세션ID가 같다.
Cache
- 클라이언트나 서버의 메모리에 저장하여 빠르게 데이터를 갖고오기 위한 임시 저장소
[ HTTP Status Code ]
서버와 클라이언트가 데이터를 주고 받으면 주고 받은 결과로 상태 코드를 확인할 수 있다.
- 2xx : success
- 3xx : redirection (browser cache) - 이미 갖고와서 저장된 데이터를 불러오는 경우 같은 상황
- 4xx : request error
- 5xx : server error
위 내용들을 정리한 그림
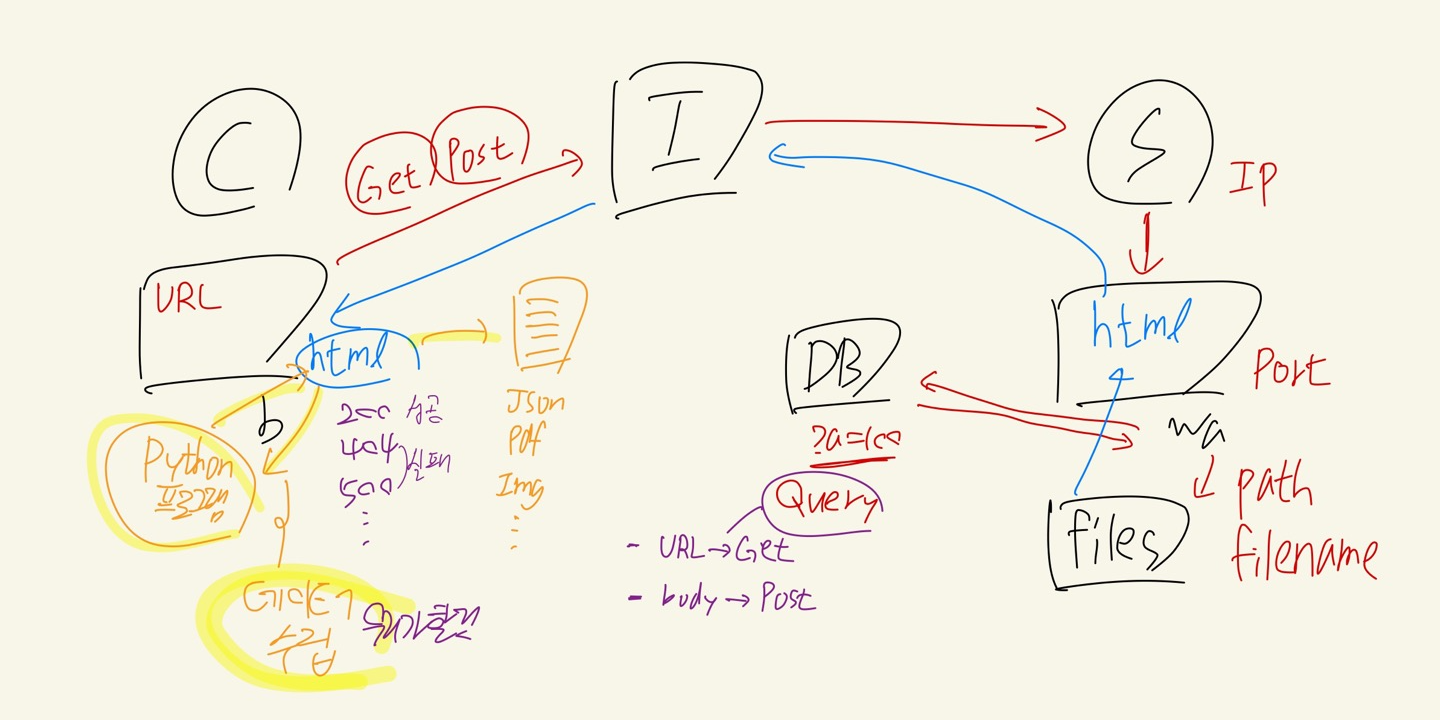
- Client가 Browser에서 Internet을 거쳐 URL을 사용하여 Server로 요청을 보낸다.
- Get 방식 사용 시 URL에 데이터 포함 / Post 방식 사용 시 데이터는 Body에 포함하고 URL과 함께 요청
- Internet의 DNS(Domain Name Server)에서 클라이언트가 보낸 도메인 주소를 받고 해당 서버의 IP주소를 알려줌 (그림에서 빠짐)
- IP주소를 받은 브라우저에서 해당IP의 서버로 요청을 보내면 URL에 맞는 포트 번호의 Web App에서 맞는 경로에 있는 파일을 갖고오고, 쿼리로 요청받은 데이터를 담아서 클라이언트에게 전달
웹 크롤링(Web Crawling)
[ 웹 페이지의 종류 ]
- 정적페이지 : 페이지의 데이터가 변경될 때 URL이 변경 O (HTML 포맷의 데이터를 받아옴)
- 동적페이지 : 페이지의 데이터가 변경될 때 URL이 변경 X (JSON 포맷의 데이터를 받아옴)
[ 웹 크롤링 기본적 절차 (동적페이지) ]
- 웹서비스 분석 : 크롬 개발자 도구 > 데이터 요청 URL 찾아내기
- request(url) > response(json) : JSON 포맷의 str 데이터 수집 (받아온 데이터는 항상 str이기 때문에 받아온 뒤에는 항상 str을 윈하는 형식으로 변환해줘야 함)
- JSON(str) > list, dict > DataFrame 변환
[ 네이버의 증권 데이터 크롤링 해보기 ]
KOSPI와 KOSDAQ의 일별 시세 데이터 크롤링
- 네이버 증권의 코스피 페이지
- 보기 편하도록 모바일 웹페이지로 확인
- 하단의 더보기 버튼을 눌러도 URL이 변경되지 않는 동적페이지임

데이터 요청 URL을 찾아내기 위해 일별 시세 항목의 [더보기] 버튼을 눌렀을 때 크롬 개발자 도구의 네트워크 탭에서 요청이 이루어지는 것을 확인해본다.
하나씩 확인해보며 데이터를 요청하는 URL을 찾는다.
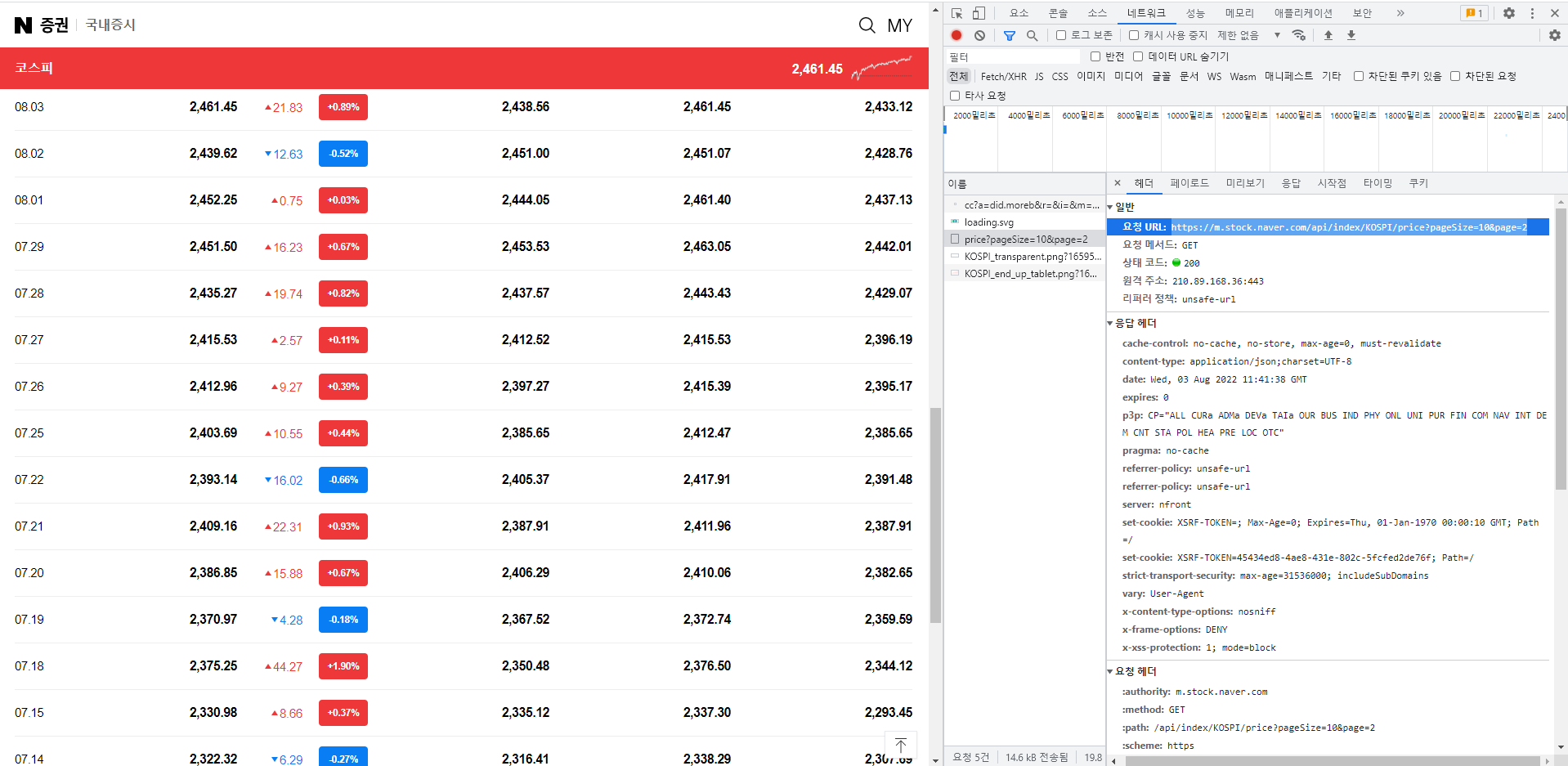
받아온 URL을 사용해 데이터를 받아와 처리하고 데이터프레임으로 반환하는 함수를 작성하였다.
def stock_price(pagesize, page, code):
"""This funcion is crawling stock price from naver webpage.
Params
------
pagesize : int : one page size
page : int : page number
code : str : KOSPI or KOSDAQ
Return
------
type : DataFrame : display date, price columns
"""
url = f"https://m.stock.naver.com/api/index/{code}/price?pageSize={pagesize}&page={page}"
response = requests.get(url)
data = response.json()
return pd.DataFrame(data)[['localTradedAt', 'closePrice']]url을 살펴보면 {code}에 해당하는 주가지수를 지정할 수 있고, {page}로 데이터의 시작 위치, {pagesize}로 받아올 데이터 개수를 지정할 수 있다.
url을 requests 패키지의 get()함수에 넣어서 요청을 보내고 받은 응답을 response 변수에 저장한다.
서버로부터 받은 응답은 문자열 형식으로 된 json의 리스트이기 때문에 이를 json()으로 풀어주고 데이터프레임으로 변환해준 뒤 필요한 칼럼만 잘라낸다.
""" """안에 있는 글은 함수의 기능에 대한 설명을 적은 Docstring이다.
함수 사용 시 해당 함수의 독스트링을 확인하려면 help()를 사용하면 된다.
*참고로 주피터노트북 에서는 shift + tab으로 바로 확인 가능
# docstring : 함수를 사용하는 방법을 문자열로 작성
# help(), shift + tab 이용
help(stock_price)
위에서 작성한 함수를 사용하여 코스피와 코스닥의 오늘을 기준으로 60일치의 데이터를 갖고왔다.
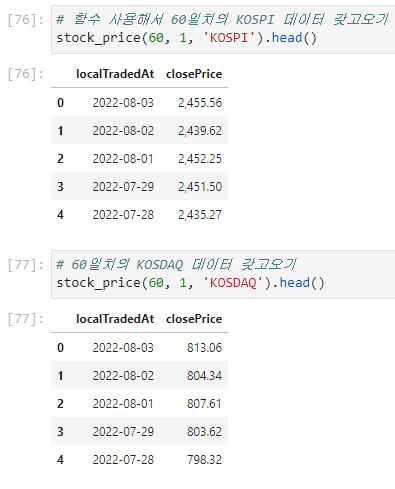
함수 호출 시 url에 들어갈 파라미터를 원하는 값으로 지정해준다.
[ 데이터의 상관관계 분석 ]
피어슨 상관계수 (Pearson Correlation Coefficient)
- 1과 가까울수록 강한 양의 상관관계를 갖는다.
- -1과 가까울수록 강한 음의 상관관계를 갖는다.
- 0과 가까울수록 관계가 없다.
피어슨 상관계수는 df.corr() 함수르 사용하여 구할 수 있다.
네이버 증권 사이트에서 코스피, 코스닥, 원-달러 환율 데이터를 수집하여 피어슨 상관계수를 구해보았다.

- kospi - kosdaq : 0.984 : 1과 가까우면 강한 양의 상관관계
- kospi - usd : -0.878 : -1과 가까우면 강한 음의 상관관계
copy() - 깊은 복사
data1 = [1, 2, 3]
data2 = data1 # 얕은 복사(call by reference) : 주소값 복사
data3 = data1.copy() # 깊은 복사(call by value) : 값 복사
print(data1, data2, data3) # [1, 2, 3], [1, 2, 3]
data1[1] = 4
print(data1, data2, data3) # [1, 4, 3], [1, 2, 3]실행 결과
[1, 2, 3] [1, 2, 3] [1, 2, 3]
[1, 4, 3] [1, 4, 3] [1, 2, 3]data1과 data2가 참조하는 메모리의 주소가 같기 때문에 data1과 data2의 출력값이 같게 나온다. (얕은 복사)
copy()를 하게 되면 새로운 메모리의 주소로 [1,2,3] 값을 복사해오는 것이기 때문에 data3의 값은 변하지 않는다. (깊은 복사)
apply(func) - 모든 데이터를 func를 적용시킨 결과를 출력
def change_ages(age):
return age // 10 * 10
df = pd.DataFrame([ {"age" : 23}, {"age" : 36}, {"age" : 27}])
df실행 결과

df["age"] = df["age"].apply(change_ages) # age 칼럼의 나이 값들을 연령대 값으로 바꿔줌
df실행 결과
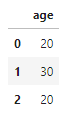
age 칼럼의 모든 데이터들을 change_ages함수를 적용한 값으로 바꿔주었다.
Lambda 함수 - 일회성 함수
간단한 함수(파라미터를 받아서 바로 리턴하는)를 메모리를 절약하여 사용할 수 있음
lambda [파라미터] : 리턴값 의 형식으로 사용한다.
*람다 함수 미사용
# 함수 3개 사용 -> 메모리 3칸 사용
def plus(n1, n2):
return n1 + n2
def minus(n1, n2):
return n1 - n2
def calc(func, n1, n2):
return func(n1, n2)
calc(plus, 1, 2), calc(minus, 1, 2)실행 결과
(3, -1)
*람다 함수 사용
# 함수 1개 사용, 메모리 1칸 사용
def calc(func, n1, n2):
return func(n1, n2)
calc(lambda n1, n2 : n1+n2, 1, 2), calc(lambda n1, n2 : n1-n2, 1, 2)
# 람다 함수는 함수가 실행될 때만 1회성으로 호출되고 사라지기 때문에 메모리를 점유하지 않음.실행 결과
(3, -1)====> 결과는 같지만 람다 함수를 사용할 때가 훨씬 메모리를 절약할 수 있고, 코드도 짧아진다.
[ API를 사용한 크롤링 - 네이버 파파고 API 사용 ]
API
- application programming interface
- api를 사용해서 데이터를 수집하는 것은 서비스에서 데이터를 제공하는 공식적인 방법으로 데이터를 수집하는 것이다.
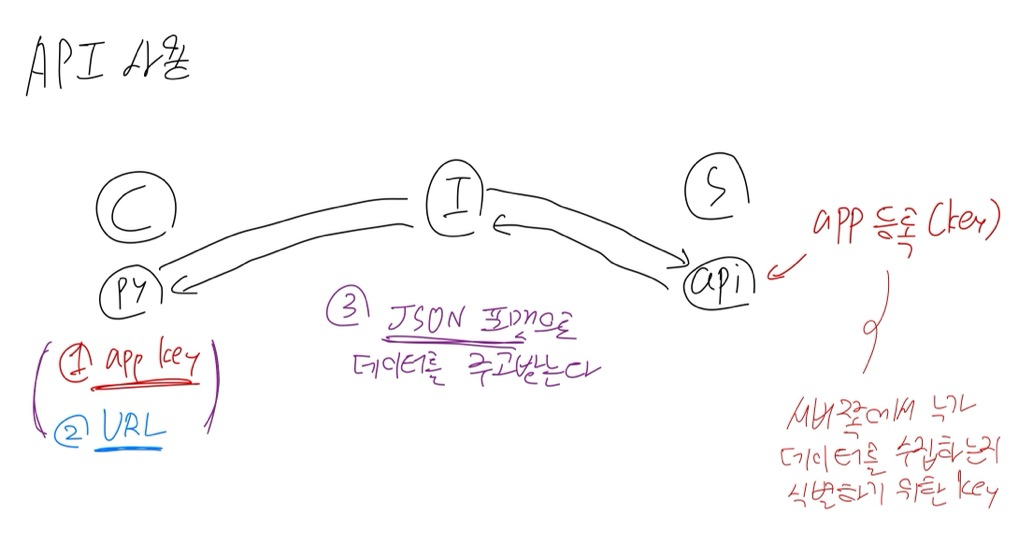
클라이언트가 서비스에서 제공되는 API를 사용하기 위해서는 서버 쪽에서 사용자를 식별하기 위한 app key를 발급받아야 한다.
key를 발급받고 나면 key와 URL을 사용하여 요청을 보내며 데이터를 주고받게 된다.
네이버의 파파고 API를 사용해서 한글 텍스트를 파파고로 번역된 영문 텍스트로 받아오는 실습을 해 보았다.
Naver Developers 사이트에서 API 사용 설명서를 보고 필요한 파라미터들과 함께 함수를 구성하였다.
인터넷 트래픽에서는 영문, 숫자, 특수문자만 사용 가능하기 때문에 한글과 같은 문자를 영문,숫자,특수문자로 인코딩 해주기 위해 json.dumps()를 사용하였다.
def translate(txt):
CLIENT_ID, CLIENT_SECRET = "발급받은 클라이언트ID", "발급받은 클라이언트Secret"
url = 'https://openapi.naver.com/v1/papago/n2mt'
params = {
"source": "ko",
"target": "en",
"text": txt,
}
headers = {
"Content-Type": "application/json",
"X-Naver-Client-Id": CLIENT_ID,
"X-Naver-Client-Secret": CLIENT_SECRET,
}
response = requests.post(url, json.dumps(params), headers=headers)
txt_en = response.json()["message"]["result"]["translatedText"]
return txt_entxt = "웹크롤링은 재미있습니다."
translate(txt)실행 결과
'Web crawling is fun.'
'KT AIVLE School' 카테고리의 다른 글
| (2주차 - 22.08.05) 웹크롤링3 (0) | 2022.08.05 |
|---|---|
| (2주차 - 22.08.04) 웹크롤링2 (0) | 2022.08.04 |
| (2주차 - 22.08.02) Python 라이브러리 활용 [데이터 분석] 2 (0) | 2022.08.02 |
| (2주차 - 22.08.01) Python 라이브러리 활용 [데이터 분석] 1 (0) | 2022.08.02 |
| (1주차 - 22.07.28~22.07.29) Python 프로그래밍 (0) | 2022.08.01 |