
[ 배운 내용 ]
Chapter 4. 쿠버네티스 개요 및 주요 아키텍쳐
Chapter 5. 쿠버네티스 클러스터 배포
Chapter 6. 쿠버네티스 컨테이너 배포, 통신, 볼륨 관리
이전의 AWS 수업에 이어서 가상머신과는 다른 가상화 방식 중 하나인 컨테이너에 대해 배웠다.
가상머신과 컨테이너의 차이점과 대표적인 컨테이너 런타임인 Docker에 대해 짧게 배웠다.
다수의 컨테이너를 관리하는 컨테이너 오케스트레이션의 대표적인 오케스트레이터인 쿠버네티스(Kubernetes)가 이번 수업의 메인 내용이었다.
쿠버네티스의 마스터노드, 워커노드의 구성요소와 각각의 역할에 대해 배우고, 쿠버네티스 클러스터의 배포 유형, 배포 순서에 대해 배웠다.
쿠버네티스의 가장 기본적인 구성단위인 Object들에는 여러 종류가 있는데 가장 대표적인 Pod, Service, Volumen, Namespace와 각각을 생성하기 위한 YAML파일의 양식도 살펴보았다.
배운 내용들을 직접 실습해보는 시간도 가졌는데 AWS로 Master, Worker1, Worker2 인스턴스를 하나씩 만들어서 마스터노드 선언, join을 해줘서 클러스터를 배포, 관리하는 실습을 했다.
Chapter 4. 쿠버네티스 개요 및 주요 아키텍쳐
대표적인 가상화 기술에는 Virtual Machine과 컨테이너가 있다.
물리적인 인프라의 가상화 기술인 가상 머신과 다르게 컨테이너는 OS 레벨의 가상화 기술이다.
Guest OS의 유무로 가상머신과 가장 큰 차이를 갖는다고 볼 수 있는데, 가상머신의 경우 Host OS 위에서 Hypervisor를 통해 Guest OS가 만들어지며 각각의 게스트 OS 위에서 app들이 돌아간다. 이는 하나의 컴퓨터에서 여러개가 가능하다. 이와 다르게 컨테이너 방식에서는 Host OS 위에서 Container Engine 위에 각각의 기능을 하는 app들이 바로 올라간다. 대표적인 컨테이너 엔진에는 Docker(도커)가 있다. 도커에 대한 설명은 따로 정리한 글이 있으니 참고하자.
컨테이너 방식 사용 시에 Guest OS를 강제로 설치할 필요가 없어서 불필요한 파일을 설치하지 않고, 가벼워진 용량으로 서비스의 배포가 가능해진다는 장점이 있다.

- 가상머신과 컨테이너 비교
| 구분 | 가상머신 | 컨테이너 |
| Guest OS | Window, Linux 등 선택 | 설치할 필요 X |
| 시작 시간 | 길다 (몇 분) | 짧다 (몇 초) |
| 이미지 사이즈 | 크다 (GB 단위) | 작다 (MB 단위) |
| 환경관리 | 각 VM마다 OS패치가 필요 | 호스트 OS만 패치 |
| 데이터 관리 | VM 내부 혹은 연결된 스토리지에 저장 | 컨테이너 내부의 데이터는 컨테이너 종료시 소멸됨. 필요시 스토리지 사용 |
서버 환경 구성방식에는 Monolithic 아키텍쳐와 MicroService 아키텍쳐가 있다.
Monolithic Architecture
- 전통적인 방식
- 고용량 고성능의 단일 서버로 구성
- 중앙집중제어가 가능
- 분리되어 있지 않기 때문에 일부의 오류가 전체적인 영향을 끼칠 수 있다.
MicroService Architecture (MSA)
- Monolithic 아키텍처에 비해 작은 서버들의 집합체로 구성
- 하나의 서버에 이상이 생겨도 재배포, 복구 등의 조치가 빠르게 이루어지고, 전체 시스템에 큰 영향을 끼치지 않는다.
컨테이너는 MSA 환경에서 적합한 기술이다.
컨테이너 오케스트레이션
마치 오케스트라의 지휘자가 지휘하듯이 다수의 컨테이너를, 다수의 시스템에서, 각각의 목적에 따라 배포/복제/장애복구 등 총괄적으로 관리하는 방식을 말한다.
소수의 컨테이너라면 도커 등의 도구로 관리가 가능하지만 다수의 컨테이너를 관리하게 된다면 컨테이너 오케스트레이션 도구를 사용하는 것이 좋다.
컨테이너 오케스트레이션 도구들은 일반적으로 다음과 같은 기능들을 제공한다.
- 스케줄링
- 자동 확장/축소 (Auto Scaling)
- 장애복구
- 로깅 및 모니터링
- 컨테이너 간 검색 및 통신
- 업데이트 및 롤백
컨테이너 오케스트레이션을 해주는 도구를 컨테이너 오케스트레이터라고 하고, 대표적으로 Kubernetes, Docker Swarm, AWS ECS, Azuer Container Instance 등이 있다.
이번 수업에서는 가장 대표적인 오케스트레이터인 쿠버네티스에 대해서 다뤘다.
CSP (클라우드 서비스 프로바이더) 3대장이라고 불리는 AWS, Azure, GCP 각각에서도 쿠버네티스 관리 환경을 제공할 만큼 쿠버네티스는 많이 쓰이는 오케스트레이터다.
Kubernetes (k8s, 쿠버네티스)
그리스어로 선박 조종사(조타수)를 뜻하는 말로 컨테이너형 애플리케이션의 배포, 확장, 관리를 자동화해주는 오픈소스 시스템이다. (이름이 길기 때문에 k8s라고 줄여서 말하는 경우가 많다.)
컨테이너 오케스트레이터로서 쿠버네티스를 사용하는 이유는 다음과 같다.
- 높은 확장성, 원활한 이동성(이식성)
- 클라우드, 로컬 or 원격 가상머신 등 여러 환경에서도 리소스만 있다면 구축이 가능
- 오픈소스
- 플러그가 가능한 모듈 형식
쿠버네티스 아키텍쳐
쿠버네티스에서 관리되는 클러스터는 크게 Master node와 다수의 Worker node로 구성된다.
- Master node는 클러스터 내의 Worker node들을 관리하는 클러스터의 제어부라고 생각하면 될 것이다.
- Worker node는 컨테이너가 직접적으로 배포되는 곳으로 실질적으로 서비스를 제어하기 위해 동작하는 요소들이라고 생각하자.
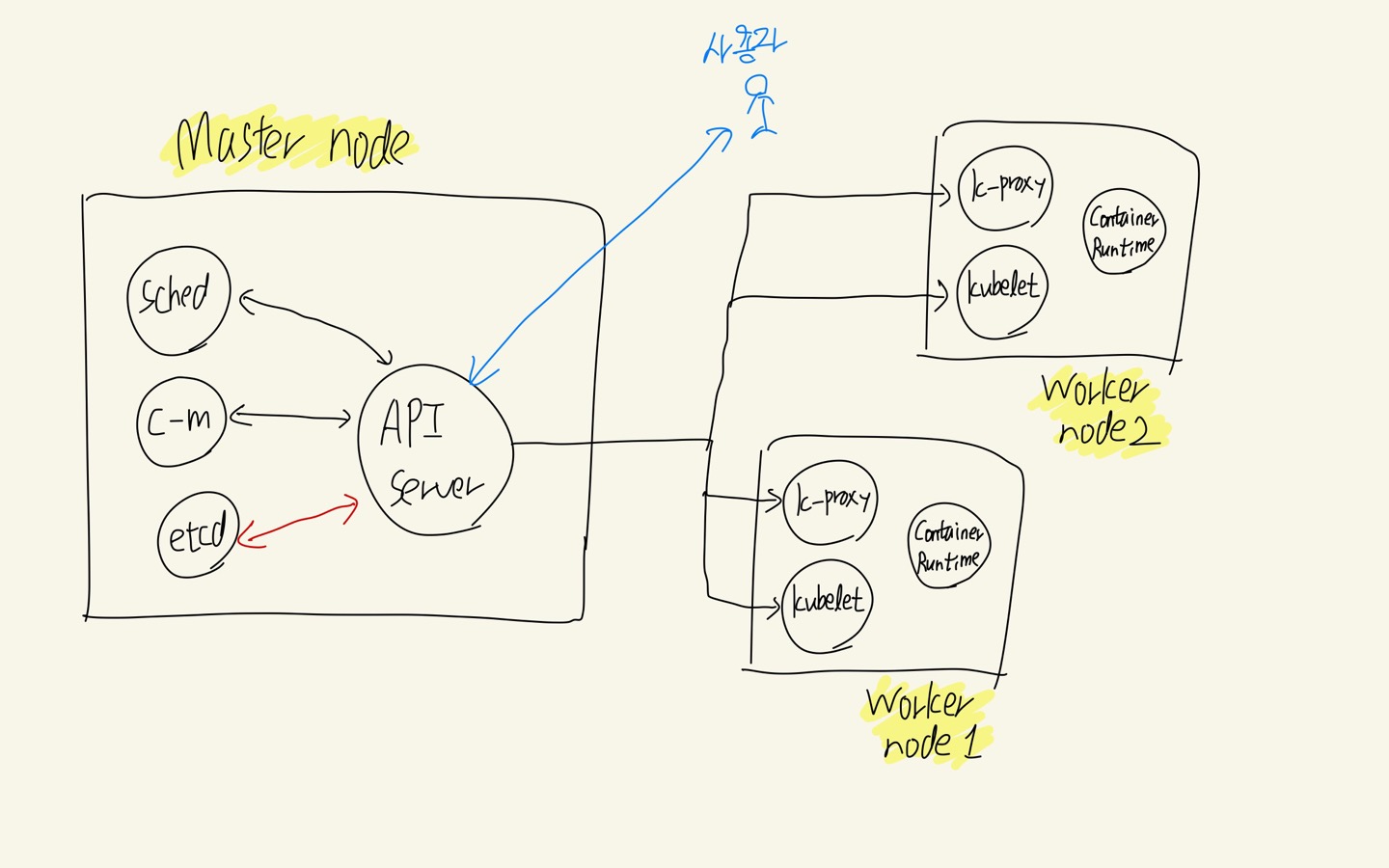
Master Node의 구성요소
Master node는 다음으로 구성이 되어 있다.
- API Server
- Scheduler
- Controller Manager
- etcd
API Server는 API(명령어)를 사용할 수 있게 해주는 프로세스로, 사용자로부터 오가는 명령어들은 반드시 API서버를 거친다.
Scheduler는 Pod의 생성 명령이 있을 경우 어떤 노드에 배포할지를 결정한다.
Controller Manager는 클러스터의 상태를 조절하는 컨트롤러들을 생성, 배포한다. 클러스터 상태를 직접 조절하는 것이 아니라 해당 일을 수행해주는 컨트롤러들을 배포하는 것이다. (controller : 클러스터 상태를 모니터링 하다가 이상이 생긴 pod이 있으면 controller에서 pod를 재배포해줌)
etcd는 모든 클러스터의 구성 데이터를 저장하는 저장소로 마스터노드에서 가장 중요한 구성요소라고 볼 수 있다. 때문에 주기적으로 백업과 이중화 등의 고가용성(HA) 조치가 필요하다.
Worker Node의 구성요소
Worker node는 다음으로 구성이 되어 있다.
- kublet
- Container Runtime
- kube-proxy
Container Runtime은 위에서 설명한 컨테이너 엔진과 같다. 노드 내에서 컨테이너를 실행하고 컨테이너 이미지를 관리해준다. 쿠버네티스에서는 도커, CRI-O 등의 컨테이너 런타임을 지원한다. (CRI-O는 k8s에서 개발한 런타임인데 최신 버전의 k8s에서는 이제 도커를 사용 못하고, CRI-O를 사용하는 것을 권장한다고 한다.)
kublet은 각 워커 노드의 에이전트로, 워커 노드의 작업반장이라고 생각하면 된다. 노드에서 이루어진 작업을 마스터 노드의 API Server로 보고하고, API Server로부터 작업 지시를 받아온다. 또한 pod 안의 컨테이너가 잘 돌아가는지도 확인해준다.
kube-proxy는 쿠버네티스 클러스터의 각 노드마다 실행되고 있으면서, 각 노드간의 통신을 담당한다.
Addons : k8s에서 추가적으로 설치하여 기능을 확장시킬 수 있는 도구
(DNS, Dachboard, Monitoring, Logging, Etc...)
Chapter 5. 쿠버네티스 클러스터 배포
쿠버네티스의 배포 유형에는 다음과 같은 방식들이 있다.
- All-in-One Signe-Node Installation (1개노드에 Master, Worker 모두)
- Single-Node etcd, Single-Master and Multi-Worker Installation (각 노드에 Master+etcd(1개), Worker)
- Single-Node etcd, Multi-Master and Multi-Worker Installation (각 노드에 Master(여러개)+etcd(1개), Worker)
- Multi-Node etcd, Multi-Master and Multi-Worker Installation (각 노드에 Master(여러개)+etcd(여러개), Worker)
4번째 방법이 고가용성(HA)까지 만족하는 가장 이상적인 방법이다.
쿠버네티스 설치 도구에는 kubeadm, kubespray, kops 등이 있는데 실습에서는 kubeadm을 사용했다.
(kubespray는 Ansible에서 사용하는 k8s 배포 도구라고 한다.)
Ansible => Infrastructure as Code (IaC)도구 (소공때 들었음)
쿠버네티스 배포 순서
- Container Rumtime 설치
- Kubernetes 설치
- Master와 Worker 연동 (join)
실습 환경에서는 AWS의 Cloud9 IDE 서비스를 사용하였고, AWS의 ECS 인스턴스 서비스로 Master, Worker1, Worker2 노드를 각각 사용했다.
Chapter 6. 쿠버네티스 컨테이너 배포, 통신, 볼륨 관리
Kubernetes Object
- 쿠버네티스의 가장 기본적인 구성 단위
- 상태를 관리하는 역할
- 가장 기본적인 오브젝트에는 Pod, Service, Volume, Namespace 가 있다.
- 오브젝트의 Spec, Status 필드
- Spec : 정의된 상태
- Status : 현재 상태
Kubernetes Controller
클러스터의 상태를 관찰하고, 필요한 경우에 오브젝트를 생성, 변경을 요청하는 역할을 담당한다.
각 컨트롤러는 관리자가 원하는 상태에 가깝도록 유지해준다. 즉, 현재 상태(Status)를 정의된 상태(Spec)에 가깝게 유지하려는 특징이 있다.
컨트롤러에는 다음과 같은 유형들이 있다.
- Deployment
- Replicaset
- Deamonset
- Job
- CronJob
[ 컨트롤러 제공 기능 ]
Auto Healing
pod에 이상이 생기면 pod을 재생성 해준다. pod은 멀쩡하지만 해당 노드에 이상이 있어도 다른 노드에 pod을 생성해준다.
Auto Scaling
리소스 부하 시 pod의 개수를 늘리거나 줄여준다.
Update & Rollback
서비스 배포 중 기능 업데이트, 버그 수정 등을 할 때 업데이트와 롤백을 수행해준다.
Job
한 번 실행되고, 종료되는 성질의 application pod을 구현하는 컨트롤러를 말한다.
Controller나 Object같은 쿠버네티스의 모든 리소스들은 YAML 파일의 형식으로 관리가 가능하다.
YAML파일 작성 시에는 공백 2칸의 들여쓰기를 꼭 지켜주어야 한다.
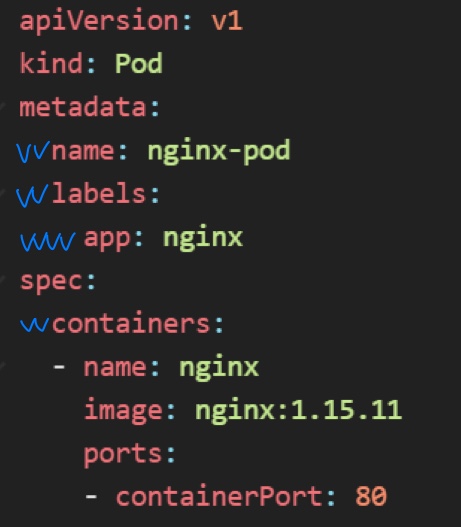
- apiVersion : 연결할 API Server의 버전
- kind : 리소스의 유형
- metadata : 리소스의 기본 정보를 갖고 있는 필드
- spec : 배포되는 리소스에 대해 관리자가 정의한 상태 (controller가 유지하고자 하는 상태)
kubectl
쿠버네티스에 명령을 내리는 CLI (Command Line Interface)
kubectl의 명령 구조는 아래와 같다
kubectl [COMMAND] [TYPE] [NAME] [FLAGS]
Pod
쿠버네티스의 가장 작은, 최소 단위 Object로 하나 이상의 컨테이너 그룹이다. 하나의 Pod 안에 있는 컨테이너들은 네트워크와 볼륨을 공유한다.
Pod에는 자가복구 업데이트 등의 기능이 없기 때문에 Controller의 관리를 받아야 한다.
[ Pod 생성 명령어 ]
- yaml파일을 사용해서 Pod 생성하는 명령어
kubectl create -f pod.yaml
kubectl create -f <yaml파일명>
- kubectl 명령으로 Pod 생성하는 명령어 (yaml파일 없이 생성 => yaml 쓰는게 훨씬 편하니 참고만 하자)
kubectl run pod \
--image=nginx:1.14.0 \
--port=80
kubectl run <pod명> \
--image=<이미지명:버전>
--port=<포트번호>
Namespace
단일 클러스터 내 리소스 그룹 격리를 위한 오브젝트로 이름도 같은 걸 보니 리눅스의 namespace와 비슷한 개념인것 같다.
클러스터 1개 내에서 사용자가 여러 팀으로 구성되는 경우 프로젝트를 진행할 때 목적에 따라 환경을 분리해야하는 경우 사용된다.
ReplicaSet (controller)
ReplicaSet은 pod의 개수를 유지해주는 controller이다.
yaml파일을 작성할 떄 replica 개수를 지정해주면 개수에 따라서 pod 개수를 유지해준다.
현재상태와 정의된 상태가 달라진다면 pod를 새로 생성하여 개수를 맞춰준다.
pod의 재배포는 Template 에 정의된 내용대로 이루어진다.

Template
- pod를 생성하기 위한 명세로 pod 세부사항을 결정한다.
- Deployment, ReplicaSet과 같은 Controller의 yaml 내용에 포함된다.
Deployment (controller)
ReplicaSet을 관리하며 애플리케이션의 배포를 더욱 세밀하게 관리하는 컨트롤러이다.
초기 배포 이후에 버전 Update와 이전 버전으로의 Rollback도 가능하다.
- ReplicaSet은 결국 Deployment의 내용을 그대로 승계받아서 pod을 배포한다.
- 업데이트 시 Deployment에 의해 업데이트 된 내용이 적용된 새로운 ReplicaSet이 새로 만들어지며, 그 ReplicaSet을 기반으로 업데이트된 pod들도 새로 만들어진다.
[ Depolyment Update ]
Deployment가 서비스 Update를 수행하기 위한 재배포에는 2가지 방식이 있다.
- Recreate : 현재 운영중인 pod를 모두 삭제하고, 업데이터 된 pod들을 생성하는 방식으로,서비스가 중단되는 Downtime이 발생한다.
- Rolling Update : 먼저 업데이트 된 pod를 하나 생성하고, 구버전의 pod를 삭제하면서 업데이트 중에도 전체 pod의 개수가 항상 유지되도록 해줌으로써 Downtime 없이 업데이트가 가능하다는 장점이 있다. 하지만 그만큼 가용 리소스를 필요로 하기 때문에 trade-off 가 있다.
[ Depolyment Rollback ]
Deployment는 이전 버전의 ReplicaSet을 10개까지 저장한다. 이렇게 저장된 이전 버전의 ReplicaSet으로의 Rollback이 가능하다.
(revisionHistoryLimit 속성을 조절해서 저장되는 ReplicaSet의 개수를 변경 가능하다.)

[ Deployment 생성 명령어 ]
- yaml파일을 사용해서 Deployment를 생성하는 명령어
kubectl create -f deployment.yaml
kubectl create -f <yaml 파일명>
- kubectl 명령으로 Deployment 생성하는 명령어 (yaml파일 없이 생성 => yaml 쓰는게 훨씬 편하니 참고만 하자)
kubectl create deployment dp \
--image=nginx:1.14.0 \
--replicas=3
kubectl create deployment <이름> \
--image=<이미지명:버전>
--replicas=<Pod수>
[ Pod Scaling ]
- Deployment로 생성된 pod 수를 조정(Pod Scaling)하는 명령어
kubectl scale deployment/dp --replicas=3
kubectl scale deployment/<Deployment명> --replicas=<조정할 pod수>
- ReplicaSet으로 생성된 pod 수를 조정(Pod Scaling)하는 명령어
kubectl scale rs/rs --replicas=3
kubectl scale rs/<ReplicaSet> --replicas=<조정할 pod수>
Service
- pod에 접근하기 위해 사용하는 Object
- 쿠버네티스 외부/내부에서 pod에 접근할 때 필요
- 고정된 주소를 이용하여 접근이 가능
- pod에서 실행중인 애플리케이션을 네트워크 서비스로 노출시키는 Object
서비스 이용자는 Service의 고정된 주소를 통해 매칭(Label, Selector)되는 Node의 pod로 접근한다.
Service의 고정된 주소로 접근하면 pod으로 알아서 매칭이 되기 때문에 업데이트 등의 이유로 pod의 IP주소가 바뀌어도 사용자는 원래 접근하던 대로 Service에 접근해서 해당 pod으로 접근이 가능하다.
- Label : pod와 같은 Object에 첨부된 key:value 쌍
- Selector : 특정 Label값을 찾아 해당하는 Object만 관리할 수 있게 연결해준다.
아래 그림을 보면 왼쪽의 Pod의 labels에 정의된 app: nginx 쌍과 오른쪽의 Service의 selector에 기재된 app: nginx를 매칭시켜서 해당 서비스로 들어온 요청이 pod으로 접근 가능하도록 해준다.


[ Service 유형 ]
- ClusterIP (디폴트) : Service가 기본적으로 갖고있는 Cluster IP를 사용하는 방식으로 클러스터 내부에서만 접근이 가능하기 때문에 내부에서 인가된 사용자나 관리자가 사용할때 사용된다.
- NodePort : 모든 노드에 포트를 할당하여 접근하는 방식으로 외부에서도 접근이 가능하다. 주로 임시연결/시연용으로 많이 사용되며, NodePort유형으로 서비스를 생성하면 ClusterIP도 발급받아서(디폴트라서) 내부 통신도 가능하다.
- Load Balancer : Load Balancer Plugin을 설치하여 접근하는 방식으로 ClusterIP + NodePort + Load Balance 서비스들을 총망라한 서비스이다. 외부에서 접근 가능한 public한 IP를 발급해준다.
- yaml파일을 사용해서 ClusterIP 유형의 Service를 생성하는 명령어
kubectl create service clusterip clip --tcp=8080:80
kubectl create service clusterip <Service명> --tcp=<포트:타겟포트>
- yaml파일을 사용해서 NodePort 유형의 Service를 생성하는 명령어
kubectl create service nodeport np --tcp=8080:80
kubectl create service nodeport <Service명> --tcp=<포트:타겟포트>
- yaml파일을 사용해서 Load Balancer 유형의 Service를 생성하는 명령어
kubectl create service loadbalancer lb --tcp=5678:8080
kubectl create service loadbalancer <Service명> --tcp=<포트:타겟포트>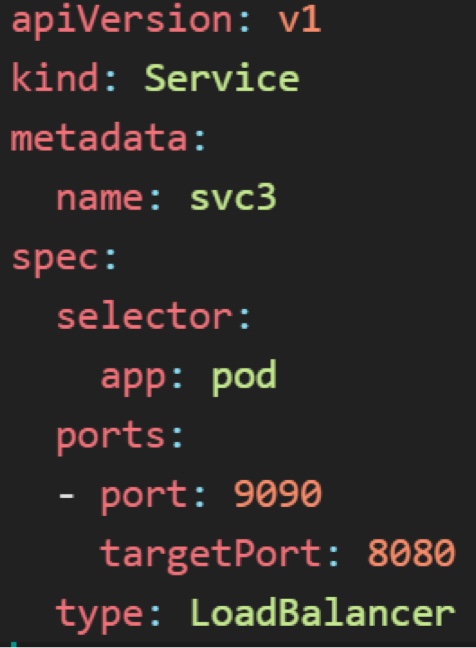
Kubernetes DNS
쿠버네티스는 Pod와 Service에 DNS 레코드를 생성해서 IP대신 이 DNS를 활용해서 접근도 가능하다.
내용이 많아졌으니 예시는 강의자료를 참고하자...
Volume
쿠버네티스에서 Volume은 pod 컨테이너에서 접근할 수 있는 디렉터리라고 생각하면 된다.
각 유형의 YAML파일 형식도 강의록을 참고하자
[ Volume 유형 ]
- EmptyDir : pod가 생성될 때 함께 생성되고, pod가 삭제될 때 함께 삭제되는 임시 Volume으로 pod 안의 컨테이너들이 공동/임시로 사용할 때 쓴다.
- HostPath : 호스트 노드의 경로(pod의 외부)를 pod에 마운트하여 함께 사용하는 유형의 Volume으로, 노드 안의 파일을 컨테이너가 사용해야 할 때 사용한다. (pod 장애 등의 이유로 pod이 새로 생성될 때 자동으로 마운트 되지 않는다.)
- PV/PVC : PV는 Persistent Volume으로 볼륨 자체를 의미한다. 클러스터 내부에서 Object처럼 관리 가능하고, pod와는 별도로 관리된다. pod에 직접 연결하지 않고 PVC를 통해 사용한다. PVC는 PersistentVolumeClaim으로 사용자가 PV에 하는 요청을 의히마녀, pod와 pv의 중간 다리 역할이다.
'KT AIVLE School' 카테고리의 다른 글
| (17주차 - 22.11.09~22.11.10) SQL - MySQL (0) | 2022.11.09 |
|---|---|
| (17주차 - 22.11.07~22.11.08) 웹 프로그래밍 - 자바스크립트 (JavaScript), Vue.js (0) | 2022.11.07 |
| (16주차 - 22.11.02~22.11.03) 가상화 클라우드1 - AWS (0) | 2022.11.03 |
| (16주차 - 22.10.31~22.11.01) IT인프라 - 가상환경, 리눅스 명령어 (0) | 2022.11.01 |
| (12주차 - 22.10.05) 언어지능딥러닝3 - CNN 기반 자연어처리 (0) | 2022.10.09 |