
[ 배운 내용 ]
1일차
1. 데이터베이스와 테이블 생성, 데이터 추가
2. 데이터 조회
3. 데이터 집계
2일차
4. INSERT, UPDATE, DELETE, 피벗, 크로스탭
5. View
6. JOIN
[ 오늘 내용 정리 ]
1일차
SQL의 기본적인 명령어들을 MySQL Workbench 환경에서 실습을 통해 배웠다.
파이썬 환경에서 MySQL의 DB를 불러오는 방법을 간단하게 배웠는데 이후 장고 시간에 다시 배울 예정이니 이런게 있구나 하고 넘어갔다.
데이터베이스를 생성,제거하고 테이블을 만드는 방법과 MySQL의 데이터 형식, 데이터를 추가하는 방법에 대해 배웠다.
이후 기본적인 데이터 조회 방법을 다뤘는데, SELECT, FROM, WHERE문을 기본으로 해서 다양하게 조건을 걸어주는 방법을 배웠다. 조건을 걸어주는 방법 중 BETWEEN, IN은 유용해 보였으니 꼭 기억하고, NULL은 값이 없다는 뜻이 아니라 값을 모른다는 뜻이라는 것도 꼭 기억하자
집계함수인 SUM, AVG, MAX, MIN, COUNT를 사용해서 집계하는 방법도 배웠고, GROUP BY와 HAVING절을 사용해서 OO별 데이터를 확인하는 방법도 배웠다. 집계함수 사용 시에 NULL값 처리에 주의하자(COUNT는 상관 없지만 나머지는 NULL값에 대한 처리 해주는게 좋음) 학교 수업으로 들었을 때 GROUP BY가 헷갈렸는데, WHERE절은 GROUP BY 이전의 조건이고, HAVING은 GROUP BY가 적용된 이후의 조건이라는 것을 기억하자
2일차
어제 배운 내용을 복습하면서, INSERT, UPDATE, DELETE를 잠깐 다루고, 피벗(크로스탭)이라고 불리는 고급 기술도 다뤄보았다.
MySQL Workbench 상에서 테이블 간의 관계를 시각화해서 보는 실습을 했고, primary key와 foreign key의 관계에 따라 다른 테이블로부터 데이터를 불러오기 위해 JOIN을 하는 법을 배웠다.
JOIN은 INNER JOIN과 OUTER JOIN으로 나뉘고, OUTER JOIN 시에는 LEFT, RIGHT, FULL을 붙여서 값을 모두 갖고올 테이블을 지정해줄 수 있다. (MySQL에서는 FULL OUTER JOIN을 제공하지 않는다!!)
또한 CROSS JOIN도 있는데, CROSS JOIN 시에는 카타시안 곱을 수행해줘서 두 테이블로 만들 수 있는 모든 경우를 만들어 준다. (각 테이블의 행 개수 곱 m*n)
JOIN처럼 사용할 수 있는 다른 방법인 서브쿼리도 배웠고, ()안의 조건을 만족하는 데이터만 찾아내는 EXISTS()문에 대해서도 공부했다.
DB Browser for SQLite를 다운받은 뒤, SQLite의 db파일도 만들어서 SQLite의 쿼리문을 간단하게 사용해보았다. (3.12.2 버전 다운로드)
https://sqlitebrowser.org/blog/version-3-12-2-released/
Version 3.12.2 released - DB Browser for SQLite
This is a minor maintenance release, primarily to update the internal certificates for anonymous communication with the DBHub.io servers. You don’t need to upgrade unless you’re using DBHub.io anonymously. If you’re using DBHub.io with your own clien
sqlitebrowser.org
SQL의 다양한 함수도 이것저것 사용해봤다 자세한 내용은 실습파일 참고하자
쿼리문을 재사용 가능하도록 해주는 View에 대해 배우고, ROW_NUMBER(), RANK(), DENSE_RANK(), NTILE()과 OVER(), PRTITION BY, ORDER BY를 같이 사용해서 순위 혹은 순서를 표현하는 방법도 배웠다.
1. 데이터베이스와 테이블 생성, 데이터 추가
- 데이터베이스 만들기
-- 기존 데이터베이스 제거
DROP DATABASE IF EXISTS mydb;
-- 데이터베이스 만들기
CREATE DATABASE mydb;
-- 대상 데이터베이스로 연결
USE mydb;
-- 현재 데이터베이스 확인
SELECT DATABASE();
테이블과 DB 모두 같은 키워드로 생성, 변경, 제거가 가능하다.
- CREATE : 생성
- ALTER : 변경
- DROP : 제거
- 테이블 만들기
-- department 테이블 만들기
CREATE TABLE department (
dept_id CHAR(3) NOT NULL,
dept_name VARCHAR(10) NOT NULL,
start_date DATE NOT NULL,
PRIMARY KEY(dept_id)
);- CHAR(3) : 고정길이 지정 (무조건 3글자)
- VARCHAR(10) : 가변길이 지정 (10글자 이내로 상관X)
- NOT NULL : 결측치 허용하지 X
-- employee 테이블 만들기
CREATE TABLE employee (
emp_id CHAR(5) NOT NULL,
emp_name VARCHAR(4) NOT NULL,
gender CHAR(1) NOT NULL,
hire_date DATE NOT NULL,
dept_id CHAR(3) NOT NULL,
phone CHAR(13) NOT NULL,
salary INT NULL,
PRIMARY KEY(emp_id),
FOREIGN KEY(dept_id) REFERENCES department(dept_id),
UNIQUE(phone)
);- DATE : 날짜 자료형
- NULL : 결측치 허용함
- UNIQUE(phone) : phone값은 중복 허용하지 X
-- vacation 테이블 만들기
CREATE TABLE vacation (
vacation_id INT NOT NULL AUTO_INCREMENT,
emp_id CHAR(5) NOT NULL,
begin_date DATE NOT NULL,
end_date DATE NOT NULL,
reason VARCHAR(50) NOT NULL DEFAULT '개인사유',
duration INT AS (DATEDIFF(end_date, begin_date) + 1),
CHECK (end_date >= begin_date),
FOREIGN KEY(emp_id) REFERENCES employee(emp_id),
PRIMARY KEY(vacation_id)
);- AUTO INCREMENT : 자동증가 속성 추가 (행이 추가될때마다 값이 증가)
- DEFAULT : 값을 따로 넣지 않으면 디폴트값으로 넣어줌
- CHECK : 조건검사 (조건을 만족하지 않으면 데이터가 추가되지 않음)
DB 테이블을 생성할 땐 이렇게 확실하게 조건을 걸어줘야 깔끔한 데이터를 지켜가며 관리할 수 있게 된다. 데이터는 아주 중요하기 때문에 확실하게 관리되어야 한다.
- MySQL 데이터 형식
MySQL에는 다양한 데이터 형식이 존재한다.
- 정수형 : TINYINT, SMALLINT, MEDIUMINT, INT(INTEGER), BIGINT
- 실수형 : FLOAT, DOUBLE(REAL), DECIMAL, NUMERIC
- 문자형 : CHAR(n), VARCHAR(n), TINYTEXT, TEXT, MEDIUMTEXT, LONGTEXT
- 날짜 시간형 : DATE, TIME, DATETIME, TIMESTAMP, YEAR
- 데이터 추가
-- 1)
INSERT INTO 테이블 VALUES(칼럼1값, 칼럼2값, ...);
ex)
INSERT INTO department VALUES('SYS', '정보시스템', '2013-01-01');
-- 2)
INSERT INTO 테이블(칼럼1, 칼럼2, ...) VALUES(칼럼1값, 칼럼2값, ...);
INSERT INTO vacation(emp_id, begin_date, end_date, reason) VALUES('S0001', '2013-01-12', '2013-01-12', '감기몸살');테이블의 모든 칼럼에 적절한 값이 들어간다면 1)번 방법처럼 칼럼명은 생략해도 된다.
-- 테이블 정보 확인
DESCRIBE 테이블;
-- 테이블 이름 변경
ALTER TABLE 테이블
RENAME TO 바꿀이름;
-- 데이터 형식 바꾸기 (SQLite는 지원하지 X)
ALTER TABLE 테이블
MODIFY 칼럼 VARVHAR(20) NOT NULL
-- 열 이름 바꾸기
ALTER TABLE employee
RENAME COLUMN phone TO tel
-- 열 추가
ALTER TABLE employee
ADD retire_date date NULL;
-- 열 삭제
ALTER TABLE employee
DROP retire_date;
2. 데이터 조회
기본적으로 아래와 같은 형식을 베이스로 생각하자 (가장 일반적인 형태)
SELECT 보려는칼럼
FROM 테이블
WHERE 조건
SELECT문에 FROM 절이 꼭 필요한 것은 아니다. 특정 값, 계산식, 함수 결과 등을 SELECT만 사용해서 조회할 수도 있다. (print문같은 느낌)
- WHERE을 사용한 조건 조회
-- MKT 부서 직원 정보 조회
SELECT *
FROM employee
WHERE dept_id = 'MKT';
- 테이블의 일부 행의 일부 열만 조회
SELECT emp_id, emp_name, dept_id, gender, hire_date
FROM employee
WHERE emp_id = 'S0001';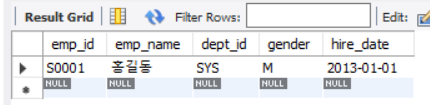
가장 바람직한 형태이다. 꼭 필요한 열과 행만을 조회하도록 하는 것이 좋다.
조건이 잘못 지정되면 오류 대신 의도하지 않는 결과를 얻을 수도 있기 때문에 본인의 코드에 겸손한 마음을 갖고 지정한 조건에 문제가 없는지 면밀하게 살펴봐야 한다.
- 비교 연산자 : =. >, <, >=, <=, <>, !=
크기를 비교할 때 사용하는 연산자로, 대부분 WHERE절에서 조건을 정의할 때 사용한다.
문자, 날짜, 숫자 모두 크기 비교가 가능하다.
-- 연봉이 7,000을 초과하는 직원 정보 조회
SELECT emp_name, emp_id, dept_id, gender, hire_date, salary
FROM employee
WHERE salary > 7000;
-- 2015년 3월 이전에 입사한 직원 정보 조회
SELECT emp_name, emp_id, dept_id, gender, hire_date, phone
FROM employee
WHERE hire_date < '2015-03-01';
-- SYS 부서가 아닌 직원 정보 조회
SELECT emp_name, emp_id, dept_id, gender, hire_date, phone
FROM employee
WHERE dept_id != 'SYS';
- LIKE 연산자
문자열 데이터는 숫자, 날짜와 달리 다양한 조건의 검색이 요구된다. 이 때 LIKE 연산자를 통해 문자열의 패턴에 조건을 걸어줄 수 있다.
-- 김씨 성을 갖는 직원
SELECT emp_id, emp_name, dept_id, hire_date, email, phone
FROM employee
WHERE emp_name LIKE '김%';
-- 이름에 '국'이 들어간 직원
SELECT emp_id, emp_name, dept_id, hire_date, email, phone
FROM employee
WHERE emp_name LIKE '%국%';
-- 이메일 아이디가 4글자인 직원
-- 언더바(_)로 개수 지정
SELECT emp_id, emp_name, dept_id, hire_date, email, phone
FROM employee
WHERE email LIKE '____@%';
-- 전화번호가 017로 시작하는 직원 정보 조회
SELECT *
FROM employee
WHERE phone LIKE '017%';
-- 전화번호가 010으로 시작하지 않는 직원 정보 조회
SELECT *
FROM employee
WHERE phone NOT LIKE '010%';
- 논리 연산자 : AND, OR, NOT
WHERE절에 여러개의 조건을 연결하는 연산자로, NOT은 조건에 대한 부정의 의미하며 다양한 다른 구문에 적용 가능하다.
-- 2016년에 입사인 직원 정보 조회
SELECT emp_name, emp_id, dept_id, hire_date, phone
FROM employee
WHERE hire_date >= '2016-01-01' AND hire_date <= '2016-12-31';
-- SYS 부서 남자 직원 정보 조회
SELECT emp_name, emp_id, dept_id, hire_date, phone
FROM employee
WHERE gender = 'M' AND dept_id = 'SYS';
- 범위 조건(BETWEEN)과 리스트 조건(IN)
WHERE절은 단순하게 표시할 수 있도록 도와주는 방법으로, WHERE을 썼을 때보다 코드가 간단해져 가독성이 좋아진다. NOT 으로 부정 조건도 지정이 가능하다.
- BETWEEN a AND b : a이상 b이하
- NOT BETWEEN a AND b : a미만 b초과
-- 2016년에 입사한 직원 정보 조회
SELECT emp_name, emp_id, dept_id, hire_date, phone
FROM employee
WHERE hire_date BETWEEN '2016-01-01' AND '2016-12-31';
- IN ( a, b, c ) : a, b, c에 포함이 되는지
-- SYS, MKT, GEN 부서 직원 정보 조회
SELECT emp_name, emp_id, dept_id, hire_date, phone
FROM employee
WHERE dept_id IN ('SYS', 'MKT', 'GEN');
- NULL값
NULL값인지 아닌지에 대한 비교는 =연산자로 하면 안된다. NULL은 값이 없다는 뜻이 아니라 값을 모른다는 뜻이기 때문에 IS NULL로 확인해줘야 한다. (NULL과 NULL은 같은 것이 아님!!)
-- 2015년도에 입사한 연봉이 6,000 이상인 근무중인 직원 정보 조회
SELECT emp_name, emp_id, dept_id, hire_date, retire_date, phone, salary
FROM employee
WHERE (hire_date BETWEEN '2015-01-01' AND '2015-12-31')
AND salary >= 6000
AND retire_date IS NULL;
- IFNULL(칼럼, 대치값) : 칼럼 값이 NULL이면 지정한 값으로 대체해준다.
-- eng_name칼럼 값이 NULL일 경우 공백 표시
SELECT emp_name, emp_id, IFNULL(eng_name, ''), gender, dept_id, hire_date, phone
FROM employee
WHERE retire_date IS NULL;참고로 DBMS마다 NULL 처리 함수가 다르다.
- MySQL : IFNULL(), ISNULL()
- Oracle : NVL()
- COALESCE() : 쿼리의 범용성을 위해 IFNULL()보다 요즘 더 많이 사용된다고 한다.
COALESCE(칼럼, a, b, c, ...) 와 같이 다른 값들을 인자로 더 추가해줄 수 있다.
SELECT emp_name, emp_id, COALESCE(eng_name, '') AS 'nick_name', gender, dept_id, hire_date
FROM employee
WHERE retire_date IS NULL;
- 문자열 결합
문자열 결합은 CONCAT() 함수로 가능하다. (문자 말고도 숫자, 날짜 등도 결합 가능하다.)
NULL값이 껴있으면 합친 값도 NULL이 되니 주의하자
-- 열 데이터 결합
SELECT CONCAT(emp_name, '(', emp_id, ')') AS emp_name, dept_id, gender, hire_date, email
FROM employee
WHERE retire_date IS NULL;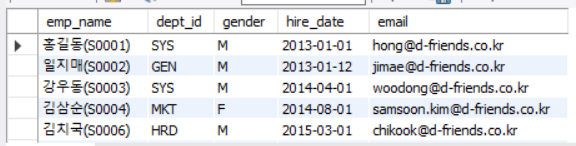
- ORDER BY 절
결과를 정렬할 때 사용한다. 정렬은 성능의 문제가 발생할 수 있기 때문에 꼭 필요한 경우에만 하도록 하자
- ASC : 오름차순
- DESC : 내림차순
-- 이름을 기준으로 오름차순 정렬
SELECT emp_name, emp_id, gender, dept_id, hire_date, phone
FROM employee
WHERE retire_date IS NULL
ORDER BY emp_name ASC;
-- 부서코드를 기준으로 오름차순, 이름을 기준으로 내림차순 정렬
SELECT dept_id, emp_name, emp_id, gender, hire_date, phone
FROM employee
WHERE retire_date IS NULL
ORDER BY dept_id ASC, emp_name DESC;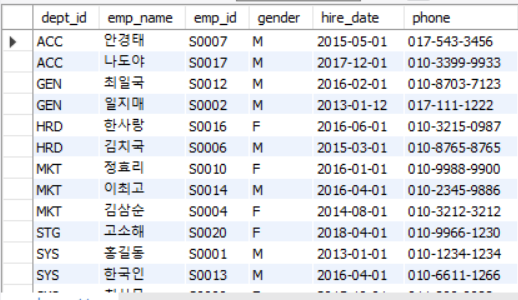
- CASE문
쿼리문 안에서 조건에 따라 다른 값 표시
CASE WHEN 조건 THEN 값
...
ELSE 마지막값 AS 칼럼
-- 성별: M, F --> 남자, 여자
SELECT emp_name, emp_id,
CASE WHEN gender = 'M' THEN '남자'
WHEN gender = 'F' THEN '여자'
ELSE '' END AS gender,
hire_date, retire_date, salary
FROM employee;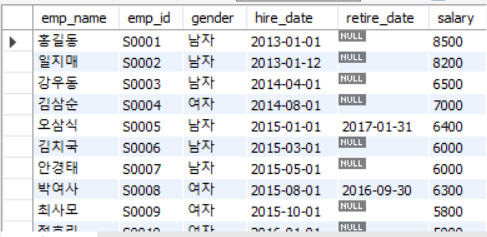
- IF 함수 : IF(조건, 참일때 값, 거짓일 때 값)
조건이 참인지 거짓인지에 따라 값을 선택한다. 조건 하나에 따라서만 값을 선택할 경우 CASE문보다 짧아서 쓰기 좋다.
-- 성별: M, F --> 남자, 여자
SELECT emp_name, emp_id,
IF(gender = 'M', '남자', '여자') AS gender,
hire_date, retire_date, salary
FROM employee;
3. 데이터 집계
[ 데이터 집계 함수 ]
- SUM()
- AVG()
- MAX()
- MIN()
- COUNT()
합, 평균값, 최댓값, 최솟값, 개수를 구해준다.
합과 평균값은 숫자에 대해서만 구할 수 있고, 최댓값, 최솟값, 개수는 문자와 날짜에 대해서도 사용이 가능하다. 날짜를 기준으로 할 때 최솟값->가장 빠른(오래된) 날짜 / 최댓값->가장 최근 날짜 를 의미한다.
집계 함수는 NULL값이 있는 행을 없는 행으로 간주하고 무시하기 때문에 NULL값이 있는 열에 대한 집계 시에 주의가 필요하다. 하지만 COUNT(*) 를 할 경우에는 특정 열을 기준으로 하지 않기 때문에 NULL값이 무시되지 않는다.
- 서브 쿼리(하위 쿼리)를 사용해서 집계 결과값과 비교하는 SQL문 작성도 가능하다.
-- 가장 최근에 입사한 직원 정보 조회 (hire_date가 가장 큰 MAX값과 같은지 확인)
SELECT *
FROM employee
WHERE hire_date = (SELECT MAX(hire_date) FROM employee);
집계 시에 NULL값이 있는 행은 고려되지 않기 때문에 AVG 같은 연산 시 실제와 다른 결과가 나올 수 있다. 따라서 NULL값인 행의 값을 0 같은 값으로 대체해서 계산해 줘야 한다.
-- NULL값 고려하지 않고 집계
SELECT AVG(salary) AS avg_salary
FROM employee
WHERE retire_date IS NULL;
-- 급여가 NULL이면 0으로 대체해서 급여 평균 조회
SELECT AVG(IFNULL(salary, 0)) AS avg_salary
FROM employee
WHERE retire_date IS NULL;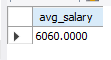

- 그룹 별 집계
그룹 별 집계 시에는 GROUP BY를 사용해준다. 집계 기준열을 지정해서 그룹별 집계를 할 수 있다.
GROUP BY 사용 시 그룹화 대상이 되는 칼럼은 SELECT문에 넣어주는 것이 좋다.
-- 남녀별 직원수 조회
SELECT gender, COUNT(*) AS emp_count
FROM employee
WHERE retire_date IS NULL
GROUP BY gender
ORDER BY gender DESC;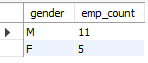
그룹 별 집계 시에 HAVING절을 사용해서 조건을 걸어줄 수 있다. WHERE과 HAVING이 모두 사용 가능한데, 조건 적용 순서가 다르다는 것을 주의하자.
- WHERE절 조건 : GROUP BY 하기 전
- HAVING절 조건 : GROUP BY 한 후
GROUP BY시에 HAVING을 필수로 사용하는건 아니지만, HAVING은 반드시 GROUP BY와 함께 쓰여야 한다.
많이 쓰이는 문법을 예시로 들어본다면,
-- 근무중인 직원이 3명 이상인 부서별 근무중인 직원 수 조회
SELECT dept_id, COUNT(*) AS emp_count
FROM employee
WHERE retire_date IS NULL
GROUP BY dept_id
HAVING COUNT(*) >= 3
ORDER BY emp_count DESC;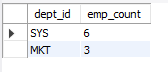
위 구문에서 실행 순서는
- 은퇴하지 않은(근무중인) 직원 중에서 : WHERE
- 부서 별로 : GROUP BY
- 3명 이상인 : HAVING
- 정렬해서 : ORDER BY
- 조회 : SELECT
이다. 근데 사실 HAVING 절에서 COUNT(*)를 SELECT문에서 지정해준 별칭인 emp_count를 써도 적용이 된다. 이는 MySQL에서만 가능한 특수한 경우기 때문에 쿼리 순서의 논리성을 위해 그냥 COUNT(*)를 써주는 것이 좋다.
- GROUP BY 시 그룹 별 지정한 칼럼값들을 한번에 보기 => GROUP_CONCAT()
GROUP_CONCAT()를 사용하면 GROUP BY 시에 그룹별 지정한 칼럼의 값들을 모두 보여준다. (구분자 설정 가능)
-- 그룹 별 salary의 총합을 보여주면서, 누가 있는지 확인
-- GROUP_CONCAT() : GROUP BY 하면서 지정된 칼럼의 값들을 모두 하나의 칼럼값으로 보여줌
SELECT dept_id,
SUM(salary) AS tot_salary,
GROUP_CONCAT(emp_name SEPARATOR '/') AS emp_name
FROM employee
GROUP BY dept_id;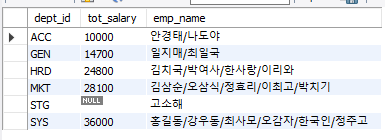
GROUP_CONCAT() 내에서 아래와 같이 정렬도 가능하다.
-- GROUP_CONCAT() 내의 데이터를 정렬하고 싶을 경우
SELECT dept_id,
SUM(salary) AS tot_salary,
GROUP_CONCAT(emp_name ORDER BY emp_name ASC SEPARATOR '/') AS emp_name
FROM employee
GROUP BY dept_id;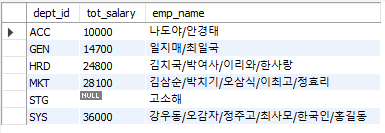
4. INSERT, UPDATE, DELETE, 피벗, 크로스탭
- INSERT : 데이터 추가
모든 칼럼을 원래 순서대로 나열해서 추가하는 경우 칼럼 이름을 생략해도 된다. 하지만 가독성 향상을 위해 열 이름을 지정하는 것이 좋다.
INSERT INTO department(dept_id, dept_name, unit_id, start_date)
VALUES('PRD', '상품', 'A', '2018-10-01');
-- 열 이름 생략
INSERT INTO department
VALUES('DBA', 'DB관리', 'A', '2018-10-01');
데이터를 변경하거나 삭제하는 작업은 매우 중요하기 때문에 신중하게 해야 한다. 수정,삭제 작업 전에 SELECT문으로 구문이 문제가 없는지 꼭 확인을 먼저 하고 작업을 해 주는 것이 좋다.
- UPDATE : 데이터 변경
UPDATE 테이블
SET 칼럼 = 변경할값
WHERE 조건-- 특정 조건의 행 UPDATE
UPDATE employee
SET phone = '010-1239-1239'
WHERE emp_id = 'S0001';
-- 홍길동(S0001)의 이름을 '홍길명'으로 변경
UPDATE employee
SET emp_name = '홍길명'
WHERE emp_id = 'S0001';
- DELETE : 데이터 삭제
-- 특정 조건에 맞는 행 지우기
DELETE FROM vacation
WHERE end_date <= '2013-12-31';
-- 모든 행 지우기
DELETE FROM vacation;
-- 모든 행 지우기 (SQLite는 제공하지 않음)
TRUNCATE TABLE vacation;
5. View
같은 쿼리를 여러개의 파일에서 사용 중일 경우 해당 쿼리의 내용이 바뀌게 되면 여러개의 파일 모두에서 쿼리문 내용을 수정해야 한다. 이런 경우 코드의 재사용이 가능해지도록 함수나 모듈을 사용하는 것처럼 View라는 것을 만들어 줄 수 있다.
- View 생성 : CREATE VIEW
CREATE VIEW 뷰이름
AS
(쿼리문 내용)
형식으로 작성해서 생성 가능하다.
-- View 생성
CREATE VIEW 근무중직원
AS
SELECT e.emp_name, e.emp_id, e.dept_id, d.dept_name, e.hire_date, e.email
FROM employee AS e
INNER JOIN department AS d ON e.dept_id = d.dept_id
WHERE e.retire_date IS NULL;
뷰를 만들었으면 아래와 같이 View의 이름만 사용해서 쿼리를 날려주면 된다.
-- View를 정의해두면 파이썬 쿼리에서는 이 쿼리만 날려주면 된다.
SELECT *
FROM 근무중직원;
- View 수정 : ALTER
ALTER VIEW 근무중직원
AS
SELECT e.emp_name, e.emp_id, e.gender, e.dept_id, d.dept_name, e.hire_date, e.email
FROM employee AS e
INNER JOIN department AS d ON e.dept_id = d.dept_id
WHERE e.retire_date IS NULL;
- View 삭제 : DROP
-- View 삭제
DROP VIEW IF EXISTS 근무중직원;
6. JOIN
다른 테이블에 있는 값을 사용하기 위해 JOIN을 해줄 수 있다. JOIN에는 INNER JOIN과 OUTER JOIN이 있다.
[ INNER JOIN ]
가장 일반적인 JOIN문 형태로, 양쪽 테이블에서 비교되는 기준값이 일치하는 행만 갖고온다. 일반적으로 primary key와 foreign key가 ON절에서 서로 비교된다. (비교되는 값이 꼭 PK와 FK일 필요는 없고, 데이터가 서로 비교 가능하기만 하면 된다. 하지만 대부분 PK와 FK를 사용한다고 한다.)
관계형 DB (RDB) 에서 테이블들은 PK와 FK를 통해 서로 관계를 맺고 있기 때문에 관계형 DB에서 JOIN은 피할 수 없는 구문이다.
- INNER JOIN 예시 (그냥 JOIN만 쓰면 INNER JOIN)
어느 테이블의 칼럼을 말하는 건지 명확히 하기 위해 테이블 이름을 명시해야 하는데, 너무 길어질 수 있으니 별칭을 꼭 사용하자
-- employee와 department테이블의 dept_id값이 일치하는 행 갖고오기
SELECT e.emp_id, e.emp_name, e.dept_id, d.dept_name, e.phone, e.email
FROM employee AS e
INNER JOIN department AS d ON e.dept_id = d.dept_id
WHERE e.hire_date BETWEEN '2014-01-01' AND '2015-12-31'
AND e.retire_date IS NULL;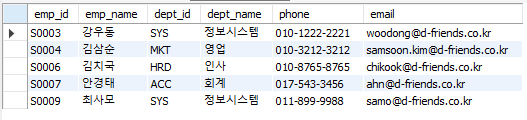
아래와 같이 여러 테이블의 JOIN도 가능하다.
SELECT v.emp_id, e.emp_name, d.dept_name, v.begin_date, v.duration, v.reason
FROM vacation AS v
INNER JOIN employee AS e ON v.emp_id = e.emp_id
INNER JOIN department AS d ON e.dept_id = d.dept_id;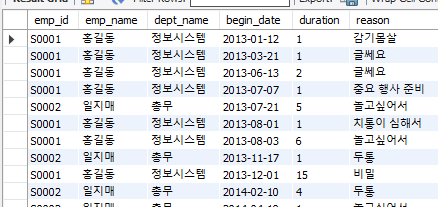
INNER JOIN 시에는 양쪽 테이블에서 mapping이 되는 경우만 결과로 반환되기 때문에 기준 칼럼값이 NULL값인 행은 JOIN되지 않는다.
[ OUTER JOIN ]
OUTER JOIN 시에는 비교되는 값이 일치하지 않는 행도 기준 테이블에서 모두 갖고온다. LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN으로 구분되는데 MySQL에서는 FULL OUTER JOIN을 지원하지 않는다고 한다.
- LEFT OUTER JOIN : 왼쪽 테이블에서 모든 값을 갖고옴 (누락된(NULL) 값도)
- RIGHT OUTER JOIN : 오른쪽 테이블에서 모든 값을 갖고옴
- FULL OUTER JOIN : 양쪽 테이블에서 모든 값을 갖고옴
- LEFT OUTER JOIN 예시
-- 모든 직원의 휴가 현황
SELECT e.emp_name, e.hire_date, e.dept_id, v.begin_date, v.reason
FROM employee AS e
LEFT OUTER JOIN vacation AS v ON v.emp_id = e.emp_id
WHERE retire_date IS NULL;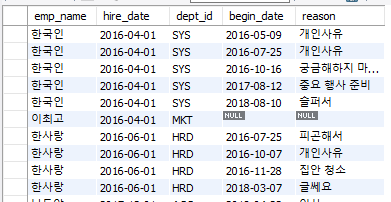
모든 직원에 대한 휴가 현황을 조회한 것이기 때문에 휴가를 가지 않은 직원에 대해서도 조회가 된다. INNER JOIN을 했었다면 휴가를 갔던 직원들만 나올 것이다.
CROSS JOIN이라는 것도 있는데, 이 조인은 ON 절이 없기 때문에 모든 경우의 수 만큼(카타시안 곱)의 결과 행을 얻는다. 대량의 샘플데이터를 만들 때 주로 사용하기 때문에 일반적인 비즈니스 응용프로그램에서 사용되지는 않는다.
- CROSS JOIN 예시
SELECT e.emp_name, d.dept_name
FROM employee AS e
CROSS JOIN department AS d;아래 결과와 같이 employee의 emp_name과 department의 dept_name의 가능한 모든 조합을 보여준다.

'KT AIVLE School' 카테고리의 다른 글
| (18주차 - 22.11.14) Web App 개발2 - 장고(Django) Template, Model간 관계 설정 (0) | 2022.11.14 |
|---|---|
| (17주차 - 22.11.11) Web App 개발1 - 장고(Django) 프로젝트 생성, Model, View (0) | 2022.11.11 |
| (17주차 - 22.11.07~22.11.08) 웹 프로그래밍 - 자바스크립트 (JavaScript), Vue.js (0) | 2022.11.07 |
| (16주차 - 22.11.03~22.11.04) 가상화 클라우드2 - 쿠버네티스(k8s) (0) | 2022.11.03 |
| (16주차 - 22.11.02~22.11.03) 가상화 클라우드1 - AWS (0) | 2022.11.03 |