
[ 오늘 배운 내용 ]
- 01 네이버 검색어 트렌드 크롤링 (동적페이지)
- 02 직방 원룸 데이터 크롤링 (동적페이지)
- 03 다음 금융 사이트 환율 데이터 크롤링 (동적페이지)
[정적페이지 크롤링]
- 04 html
- 05 css selector
- 06 네이버 연관검색어 키워드 크롤링 (정적페이지)
- 07 지마켓 베스트셀러 데이터 크롤링 (정적페이지)
실습을 시작하기 전에 robots.txt를 확인해서 TED 사이트의 크롤링 정책을 확인해보았다. 크롤링을 잘못 하게 되면 나중에 문제가 될 수 있으니 되도록이면 크롤링 하기 전 해당 사이트의 크롤링 정책을 확인하는 것이 좋을 것 같다.
오늘은 지난 시간에 발급받은 네이버에 등록한 내 앱 key로 네이버 데이터랩의 API를 사용해서 트위터,페이스북,인스타그램 각 키워드의 검색어 트렌드를 수집해보았다. requests요청에 url뿐만 아니라 params와 headers 값도 넣어주었고, 파라미터에 한글이 들어가기 때문에 json.dumps()를 넣어서 컴퓨터가 해석 가능한 문자로 바뀌도록 해 주었다.
실습 뒤에 파이썬의 유용한 기능 중 하나인 list comprehension을 사용해서 불필요한 반복문 코드를 줄일 수 있었고, matplotlib가 아니라 판다스로도 간단한 그래프를 확인할 수 있다는 것을 알았다.
다음에는 직방 사이트에서 원룸 매물정보를 수집하는 실습을 해 보았다. 이 실습은 좀 어려운 편이었는데 매물 데이터를 수집하려면 요청 url에 들어가는 매물의 item_id값을 알아야 했다. 이 item_id를 알기 위해선
위도,경도 -> geohash값 -> 매물의 item_id의 순서로 요청을 보내면서 값을 받아와야 했다. 이런 부분은 직접 개발자 도구를 통해 트래픽들을 확인해가며 찾아야 한다고 강사님이 말씀하셨다.
과정은 꽤 복잡했지만 정말 실전 같은 실습이어서 재미있었다.
작성한 코드들을 하나의 함수로 합쳐주었고 그 쉘을 파이썬 파일로 저장한 뒤 불러와서 사용하는 실습도 해보았다.
이 때 사용되는 주피터노트북의 매직 커맨드들에 대해서도 강사님이 몇가지 알려주셨다.
다음으로 다음 금융 사이트의 환율 정보를 수집했는데 여기서는 get 요청을 사용하지만 headers도 별도로 추가해 주어야 했다. 다음 금융에서는 네이버 금융과 다르게 헤더에 user-agent와 referer값을 넣어서 요청을 보내주어야 데이터를 응답으로 받을 수 있었다.
다음으로 정적페이지에서 데이터를 수집하는 실습을 해 보았다.
정적페이지에서 데이터를 수집할 때에는 html 형식의 데이터를 받아오기 때문에 여기서 데이터들은 html 의 엘리먼트 들에서 추출해와야 한다. 이를 위해 BeautifulSoup 라이브러리가 필요하고 html과 css 선택자에 대한 지식도 필요하다. 때문에 실습에 앞서 HTML과 CSS Selector에 대해 간단한 설명을 듣고 실습을 시작했다.
네이버에 kt를 검색했을 때 하단에 나오는 연관검색어들을 수집해보는 실습을 했다.
엘리먼트 요소를 찾을 때는 개발자 도구에서 요소 찾기를 누르고 마우스만 갖다 대면 찾아준다. 게다가 css선택자까지 우클릭으로 바로 복사할 수 있기 때문에 뭔가 더 쉬운 듯한 느낌이었다.(아님말고)
찾아낸 css 선택자를 사용하여 BeautifulSoup에서 원하는 데이터를 뽑아올 수 있었다.
오늘의 마지막 실습으로 지마켓의 베스트셀러 데이터를 수집해보았다.
아래는 실습한 내용을 그대로 기록한 건 아니고 실습하면서 유용해 보이는 정보들을 기록했다.
01 - 네이버 검색어 트렌드 크롤링
- 크롤링 정책
크롤링 정책을 확인하고 싶을 때에는 해당 웹사이트의 robots.txt 파일을 확인한다. ex) https://www.ted.com/robots.txt
예시로 TED의 robots.txt를 확인해보았다.
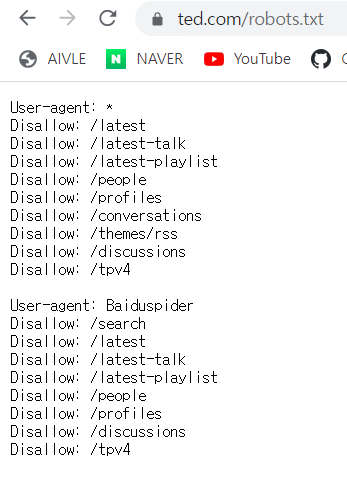
User-agent
- 클라이언트에 대한 정보 (=클라이언트가 누군지에 대한 정의)
- request요청에 담아서 서버로 보내준다.
- *는 모든 클라이언트에 대해 허용
위 사진에서는 모든 클라이언트에 대해 허용하지만 'Baiduspider'는 거부
Disallow
- 접근 불가 경로
list comprehension
: 파이썬에서 간단한 for, if문을 사용하여 리스트 데이터를 만들 때 사용하는 방법
ex) 0 ~ 9까지 홀수만 제곱해서 리스트를 출력
# for문 돌아가면서 리스트에 넣어주고 if문으로 필터링 한 뒤
# 남은 애들을 리스트 앞부분에서 지정한 대로(num**2) 만들어줌
result = [num**2 for num in range(10) if num % 2]
result출력 결과 : [1, 9, 25, 49, 81]
판다스로 간단하게 그래프 그려보기
df.plot()을 사용하면 matplotlib이 아니라 판다스로도 간단하게 그래프를 그릴 수 있다.
df.plot(figsize=(20,5))실행결과

02 - 직방 원룸 데이터 크롤링
주피터 노트북 매직커맨드
%%를 사용한 커맨드는 해당 코드 셀 전체대 대해 실행되는 Cell 매직 명령어 이다.
% : 해당 라인에 대해 실행
- %%writefile : 해당 쉘을 .py 파이썬 모듈 파일로 저장
- %reset : 현재 노트북 파일에서 메모리에 할당된 변수 리스트를 모두 삭제
- %whos : 현재 노트북 파일에서 메모리에 할당된(선언된) 변수 리스트 보기
@@주의) 셀 안에서 %%커맨드 위에 다른 커맨드가 있으면 안된다 (주석도 안됨)
*요청 URL에 한글 등이 포함되어 있어서 인코딩이 깨져있을 경우
아래 사이트에서 url의 원본을 확인하여 갖고올 수 있다.
https://meyerweb.com/eric/tools/dencoder/
URL Decoder/Encoder
meyerweb.com
03 - 다음 금융 사이트 환율 데이터 크롤링
다음 금융 사이트로 요청을 보낼 때도 네이버 금융 페이지와 같이 get 요청을 보냈지만
응답 결과로 403에러가 나온 것을 볼 수 있다.

위와 같이 get 요청 시 이상이 없는 것 같은데 에러가 뜬다면 해당 웹앱의 백엔드에서 요청의 헤더(header)의 내용을 별도로 검사하도록 되어 있는 것이기 때문에 헤더에 대한 내용도 같이 포함해서 요청을 보내야 한다.
파이썬으로 user-agent를 따로 설정하지 않은 채로 요청을 보내면 user-agent는 '파이썬'인 것으로 요청이 가는데, 이 때 별도 설정을 하지 않아도 응답이 잘 돌아오는 사이트라면 별도의 헤더 설정을 해 주지 않아도 되는 사이트고, 응답이 잘 오지 않는다면 헤더를 검사하도록 되어 있는 사이트인 것이다.
이런 사이트로 user-agent가 '파이썬'인 요청이 오면 일반적인 OS가 아니기 때문에 정상적이지 않은 사용자로 간주하여 접근을 거부하는 것이다.

보통 use-agent -> referer -> cookie 를 하나씩 넣어보면 대부분 된다고 하셨다.
다음 금융 사이트의 경우는 헤더에 user-agent와 refere를 넣어서 요청을 보내니까 됐다.
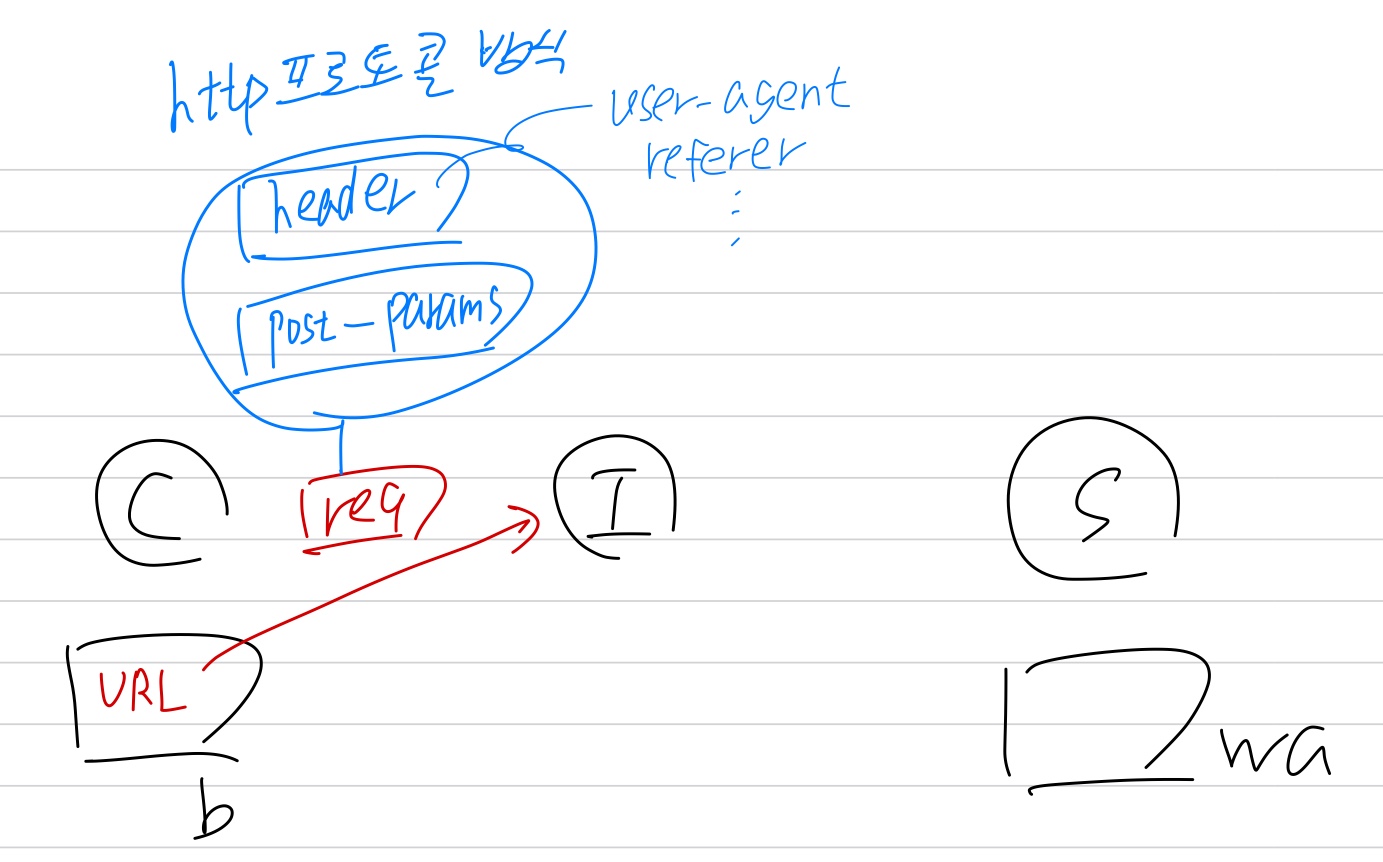
get 요청과 post 요청
get 요청은 url만 포함해도 되지만 post 요청은 url 뿐만 아니라 params도 포함해주어야 한다.
header는 post와 get 요청에 모두 포함할 수가 있다.
04 - HTML
HTML
- 웹 문서를 작성하는 언어
- 구성요소
- Document : 한 페이지를 나타내는 코드
- Element : 하나의 레이아웃 : Element가 모여서 Document를 만듦
- Tag : Element의 종류를 정의 : 시작태그 + 끝태그 = Element
- Attribute : 속성값 : 시작태그에서 태그의 기능 정의
- id : element를 지정하는 페이지 내에서 유일한 값
- class : element를 지정하는 값으로 페이지 내에서 여러개 사용 가능
- attr : id, class를 제외한 나머지 속성값
- Text : 시작태그와 끝태그 사이의 문자열
- Element는 계층적 구조를 갖는다.
HTML 태그 종류
- <p> : 한 줄의 문자열을 출력
- <span> : 한블럭의 문자열 출력
- <ul>, <li> : 리스트 문자열 출력
- <a> : 링크를 나타내는 태그
(target='_blink' : 새 탭에서 열리도록 해주기) - <img> : 이미지를 출력하는 태그
- <iframe> : 외부 URL 링크에 해당하는 웹 페이지를 출력
- <div> : 레이아웃을 나타내는 태그
- <table> : 행열 데이터를 출력 (홈페이지 게시판 곳에서 게시글들에 주로 사용)
부동소수점 에러
- 컴퓨터가 소수점 연산을 할 때 이진수로 바꿔서 연산하기 때문에 발생하는 문제

위 코드를 보면 data1과 data2를 더했을 때 0.3이 아니라 살짝 더 큰 값이 나온다.
해결방법 1 : 반올림 사용 : round()
round(data1 + data2, 1), round(data1 + data2, 1) == 0.3 # 1 -> 옵션(소수점 첫째짜리까지 반올림)실행결과
(0.3, True)
해결방법 2 : 고정소수점 방식으로 연산
from decimal import Decimal
float(Decimal(str(data1)) + Decimal(str(data2))) == 0.3실행 결과 : True
==> 고정소수점 방식보단 round()가 실행속도도 더 빠르고 간단하다.
05 - CSS selector (CSS 선택자)
CSS 선택자 (CSS Selector)
CSS 스타일을 적용 시킬 HTML 엘리먼트를 선택하는 방법이다.
[ 엘리먼트 하나 선택 ]
1. Element Tag 이름으로 선택
: 태그이름
2. Tag의 id 값으로 선택
: #id값
3. Tag의 class 값으로 선택
: .class값
4. Tag의 attr 값으로 선택
: [ attr = 'attr값' ]
[ 엘리먼트 여러개 선택 ]
5. 특정 엘리먼트 제외 (not selector )
: .class1:not(.class2)
====> class1클래스의 엘리먼트를 모두 선택하는데 class2클래스이기도 한 엘리먼트는 제외
6. n 번째 엘리먼트 선택
: .class1:nth-child(2)
====> class1클래스의 엘리먼트 중 2번째 엘리먼트 선택 (0 말고 1부터 셈)
7. 계층적으로 엘리먼트 선택
: > : 한 단계 하위의 p태그
ex) .wrap > p (.wrap클래스 엘리먼트의 한단계 하위의 p태그 선택)
: 공백 : 하위 단계의 모든 p태그
ex) .wrap p (.wrap클래스 엘리먼트의 하위 단계의 모든 p태그 선택)
8. 여러개의 엘리먼트 선택
: 그냥 ,로 구분하면서 여러개 입력
ex) .py1, .py3
====> .py1클래스와 .py3클래스 엘리먼트 모두 선택
06 - 네이버 연관검색어 키워드 크롤링
정적페이지에서의 데이터 수집은
HTML 기반의 데이터를 불러와야 하기 때문에 bs4패키지의 BeautifulSoup 라이브러리를 통해 CSS 선택자를 사용해야 한다.
BeautifulSoup의 select()로 CSS 선택자를 사용하여 원하는 엘리먼트를 선택하여 원하는 문자열을 갖고올 수 있다.
- select() : 엘리먼트 여러개 선택
- select_one() : 엘리먼트 한개 선택
응답으로 받은 HTML 데이터(response)를 텍스트로 넘긴 다음 BeautifulSoup 객체로 변환해준다.
dom = BeautifulSoup(response.text, 'html.parser')
type(dom) # BeautifulSoup 클래스를 갖는 객체실행결과
bs4.BeautifulSoup
html 코드에서 연관검색어 요소를 찾고 select()를 사용해 .lst_related_srch 클래스의 하위의 .item클래스 요소들을 elements 리스트로 만들어주었다.
elements = dom.select('.lst_related_srch > .item')
len(elements)실행결과
10실행결과를 보면 10개의 연관검색어 요소들을 갖고왔다는 것을 알 수 있다.
각 연관검색어 요소들의 키워드 데이터만 빼서 keywords 리스트로 저장해준다.
keywords = [element.select_one('.tit').text for element in elements]
print(keywords)실행결과
['삼성전자', 'kt 고객센터', 'kt 인터넷', 'ky', '환율', 'kr', '날씨', 'kt 대리점', 'SKT', 'kt 고객센터 전화번호']'kt'를 검색했을 때 나오는 10개의 연관검색어들을 갖고온 것을 확인할 수 있다.
'KT AIVLE School' 카테고리의 다른 글
| (3주차 - 22.08.08) 데이터 처리1 (0) | 2022.08.08 |
|---|---|
| (2주차 - 22.08.05) 웹크롤링3 (0) | 2022.08.05 |
| (2주차 - 22.08.03) 웹크롤링 1 (0) | 2022.08.03 |
| (2주차 - 22.08.02) Python 라이브러리 활용 [데이터 분석] 2 (0) | 2022.08.02 |
| (2주차 - 22.08.01) Python 라이브러리 활용 [데이터 분석] 1 (0) | 2022.08.02 |