
[ 오늘 배운 내용 ]
1. Python 라이브러리 리뷰
2. merge, concat
3. rolling, shift
4. date, pivot, crosstab, diff 등
데이터 처리 수업을 본격적으로 시작하기에 앞서서 이전에 배웠던 pandas 라이브러리 사용법을 상기시키기 위해 강사님과 함께 여러 실습을 진행했다.
.loc와 iloc일 때의 행조건과 열조건의 차이를 확실하게 알게 되었고, 그 밖에 groupby, between, cut, drop 등 배웠던 내용들을 다시 한 번 복습해볼 수 있었다.
그 뒤에 pandas의 Merge와 Concat, Rolling과 Shift, 그리고 추가적으로 crosstab, heatmap, pivot 등 추가적인 개념도 배우며 실습해보았다.
지난 파이썬 라이브러리 수업의 연장선 느낌이었고, 여러 코드를 실행해보면서 판다스와 데이터프레임에 더 익숙해질 수 있는 수업이었다.
이번 시간에는 CRISP-DM 모델에서 3번째 step에 해당하는 Data Preparation 부분 위주의 수업이 이루어졌다.

[ Merge와 Concat ]
Merge(Join)
: 학교 데이터데이스 수업 시간에 배웠던 Join과 비슷한 개념을 데이터프레임에 적용하는 메소드이며 두 데이터 프레임을 특정 열(key) 기준으로 결합해준다.
메소드의 기본적인 구성은 pd.merge( df1, df2, how=' ', on='col1') 이다.
결합할 데이터 프레임을 차례로 파라미터로 넣어주고, how의 값으로는 left, right, inner, outer가 들어갈 수 있다. (디폴트 : inner)
on 값도 지정되지 않은 상태라면 자동으로 key를 잡아준다.
- left : df1의 col1 칼럼을 기준으로 결합한다.
- right : df2의 col1 칼럼을 기준으로 결합한다.
- inner : inner join을 수행해주며 교집합처럼 생각하면 된다.
- outer : outer join을 수행해주며 합집합처럼 생각하면 된다.
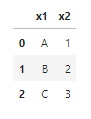
직접 임의의 데이터프레임을 두개 만들고 종류 별로 merge 해보았다.
adf = {
'x1': ['A', 'B', 'C'],
'x2': [1, 2, 3]
}
bdf = {
'x1': ['A', 'B', 'D'],
'x3': ['T', 'F', 'T']
}
adf = pd.DataFrame(adf)
bdf = pd.DataFrame(bdf)
display(adf)
display(bdf)

4가지 방법으로 merge
how='left'
# adf(left)의 x1 칼럼 기준으로 merge
pd.merge(adf, bdf, how='left', on='x1')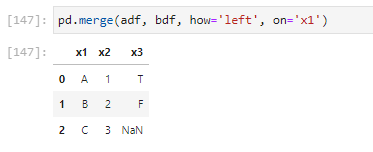
how='right'
# bdf(right)의 x1 칼럼 기준으로 merge
pd.merge(adf, bdf, how='right', on='x1')

참고로 NaN값의 자료형은 float으로 돼있기 때문에 같은 칼럼의 다른 값들이 float 형으로 바뀐다.
how='inner'
# adf와 bdf를 inner join
pd.merge(adf, bdf, how='inner', on='x1')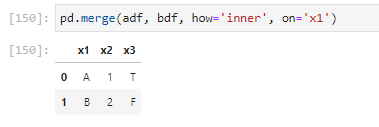
how='outer'
# adf와 bdf를 outer join
pd.merge(adf, bdf, how='outer', on='x1')
Concat
: 두 데이터 프레임을 위아래로, 혹은 옆으로 통째로 합쳐준다.
pd.concat( [ df1, df2 ], axis=0 )
- axis=0 : 행을 축으로 (위아래로 붙이기)
- axis=1 : 열을 축으로 (옆으로 붙이기)
pd.concat([adf, bdf], axis=0)
pd.concat([adf, bdf], axis=1)
[ Rolling와 Shift]
rolling()
: 주로 시계열 데이터에 대해서 이동평균값을 구하거나, 행을 이동(shift)시킬 때 주로 사용한다. 시간의 흐름에 따라 일정 기간 동안의 평균, 최댓값, 최솟값 등 여러 수치 계상 연산을 수행해준다.
- rolling()안에는 수치계산에 사용할 윈도우의 크기를 설정해준다.
- rolling의 min_periods 옵션에는 이동하는 평균값을 구성하는 개수의 최소치이다.
- shift()는 지정한 수 만큼 아래로 칸을 이동해준다. (디폴트는 1이고, -일 경우 위로 이동)
'Date', 'Close', 'Volume'의 3가지 칼럼으로 이루어진 데이터프레임에 대해서 rolling과 shift를 수행해 준 예시이다.
# 기준일을 포함한 과거 3일간의 평균값들
stock['Close_MA_3'] = stock['Close'].rolling(3).mean()
# 위에서 구한 과거 3일간의 평균값들을 한칸씩 밑으로
stock['Close_MA_3_lag1'] = stock['Close_MA_3'].shift()
# 이동평균(rolling)과 하루 뒤로 미루는(shift) 작업을 한꺼번에
stock['Close_MA_3_lag1_2'] = stock['Close'].rolling(3).mean().shift()
# 3일간의 데이터가 모이지 않아도 1개 이상만 있으면 평균을 구해준다.
stock['Close_MA_3(2)'] = stock['Close'].rolling(3, min_periods=1).mean()
stock.head()
[ +Alpha - 참고내용]
Date
판다스의 날짜형 데이터 자료형
df[ 'date' ] = pd.to_datetime( df[ 'date' ] , format = ' %Y%m%d%H ')
'date'칼럼의 내용을 날짜형 데이터 자료형으로 변환해준다. (디폴트는 YYYY-MM-DD의 문자열 형식이어야 함)
format 옵션으로 변환하려는 문자열의 날짜 형식을 알려줄 수 있다.
그 밖에 일, 월 등 원하는 단위로 끊어서 시계열 데이터 조회,
날짜 결측치 NaN값 채우기 등이 가능하다. (머신러닝수업 시계열 노트북파일 참고)
- format 지정
pd.to_datetime('2021100101', format='%Y%m%d%H')
# Timestamp('2021-10-01 01:00:00')
pd.to_datetime('2021-01-01 01:00', format='%Y-%m-%d %H:%M')
# Timestamp('2021-01-01 01:00:00')
- 날짜 자료형에서 요일, 주차, 연, 월 불러오기
dt['DateTime'].dt.dayofweek # 요일
dt['DateTime'].dt.week # 주차
dt['DateTime'].dt.year # 연
dt['DateTime'].dt.month # 월dt.dayofweek는 0~6의 정수로 표현되는데
월요일=0 ~ 일요일=6 을 의미한다.
Crosstab
: 두 범주형 변수에 사용 가능한 판다스의 교차표 함수
pd.crosstab( df[ '범주형1' ], df[ '범주형2' ] )
pd.crosstab(titanic['Survived'], titanic['Embarked'])
normalize 옵션
- 'columns' : 각 칼럼별 비율
- 'index' : 각 행별 비율
- 'all' : 전체에 대한 비율
그 밖에도 pivot과 heatmap을 사용하여 두 범주 집계를 시각화 하거나
diff() 메서드를 사용하여 지정된 만큼의 이전 시점과의 차이를 구하는 등의 실습을 해 보았는데 이 내용들은 그렇게 비중있게 다루지는 않아서 우선 merge, concat, rolling, shift 등의 내용을 잘 기억하자
'KT AIVLE School' 카테고리의 다른 글
| (3주차 - 22.08.10) 데이터 분석 및 의미 찾기 1 (0) | 2022.08.10 |
|---|---|
| (3주차 - 22.08.09) 데이터 처리2 (0) | 2022.08.09 |
| (2주차 - 22.08.05) 웹크롤링3 (0) | 2022.08.05 |
| (2주차 - 22.08.04) 웹크롤링2 (0) | 2022.08.04 |
| (2주차 - 22.08.03) 웹크롤링 1 (0) | 2022.08.03 |