
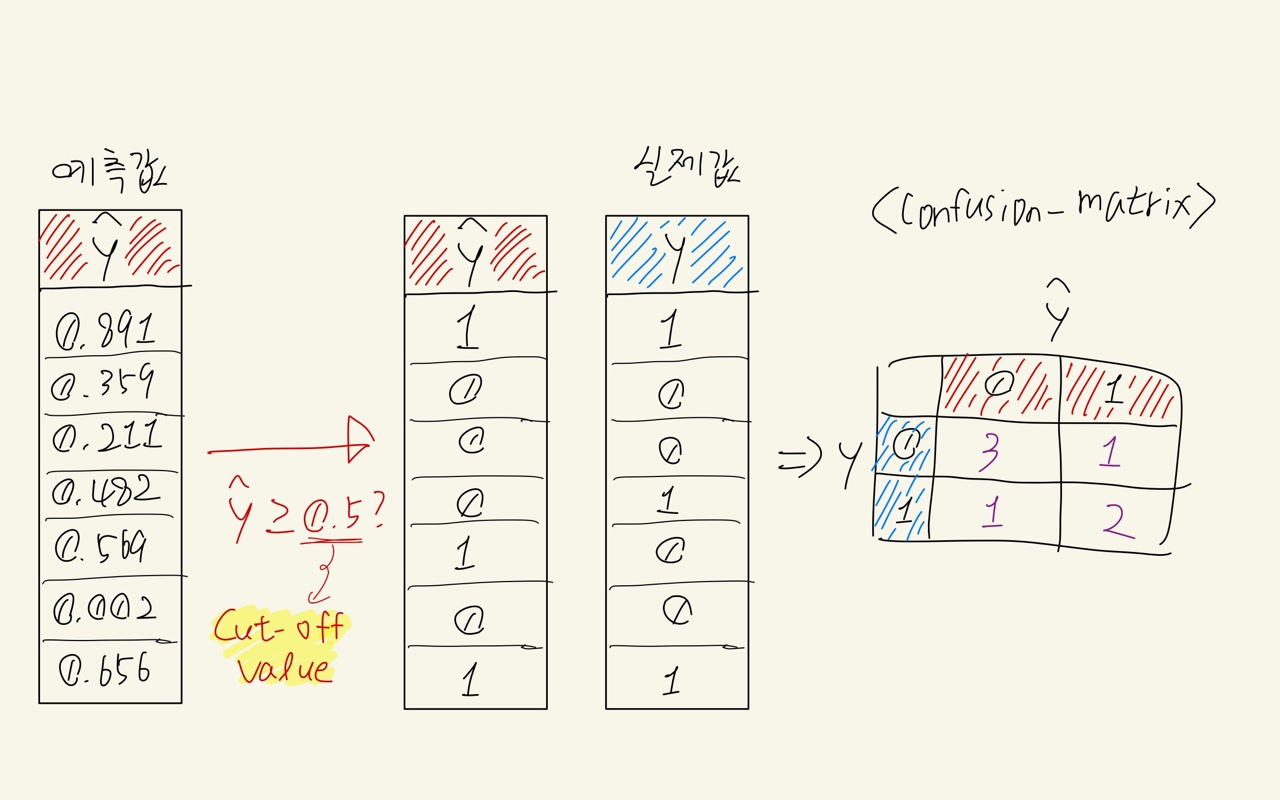
분류 모델 사용 시, 예측 결과를 보면
1, 0
Survived, Died,
Leave, Stay
등과 같이 Class(클래스)로 나오는 것 처럼 보인다.
하지만 이 결과는 바로 저렇게 예측되는 것이 아니고, 예측된 값을 가지고 만들어 낸 값이다.
분류 모델에 의해 예측된 값들은 실제 값과 함께 confusion matrix(교차집계표)를 만들어서 평가한다.
이를 위해서는 예측 결과값이 0과 1로 나와야 한다.
하지만 분류 모델들의 실제 예측 결과는 사실 0,1의 값이 아니고, 확률 값이다.
예측된 확률 값들을 어떠한 기준으로 잘라서 0과 1로 나누는 것이다.
이 때 예측된 확률 값을 자르는 기준이 되는 값을 Cut-off value (=Threshold) 라고 부른다. (디폴트는 0.5)
cut-off value를 어떻게 지정해주는지에 따라서 confusion matrix도 달라지고, 이를 기반으로 구하는 accuracy, recall, precision, f1 등의 평가지표 값들도 달라진다.
각 알고리즘이 확률로 예측하는 방법
- 로지스틱 회귀 : 선형 판별식( f(x) )의 결과를 로지스틱 함수로 변환( p(x) )
- Decision Tree : Leaf node 데이터의 y의 평균값으로 예측값을 계산
- KNN : 가까운 k개 이웃의 y의 평균으로 예측값 계산
- 랜덤 포레스트 : 각 tree가 예측한 값들의 평균으로 최종 예측값 계산
- SVM : svm은 모델 차제가 분할 경계면(선) 이므로, 결과가 바로 0,1로 나온다.
[ 실습 코드 ]
심장마비가능성을 예측하는 로지스틱 회귀 모델을 만들어보았다.
model = LogisticRegression()
model.fit(x_train, y_train)
- .predict 말고 .predict_proba로 예측을 수행하면, 각 클래스별 확률값으로 결과를 반환할 수 있다.
pred = model.predict_proba(x_val)
pred[:5]
# array([[0.98836681, 0.01163319],
# [0.10368003, 0.89631997],
# [0.02955314, 0.97044686],
# [0.57733637, 0.42266363],
# [0.08175166, 0.91824834]])
# 1일 확률만 사용
result = pd.DataFrame({ 'predicted': pred[:, 1], 'actual': y_val.values})
- np.linspace로 0~1사이의 값을 조금씩 증가시키면서 성능평가결과를 저장해주었다.
# 결과를 저장할 빈 리스트
acc, rec, prec = [],[],[]
# 0부터 1까지 cutoff값을 조금씩 증가시키며, 성능 평가결과 저장
cutoff_values = np.linspace(0, 1, 200)
for cutoff in cutoff_values :
# cutoff값 기준으로 나누어진 0과 1의 값으로 저장
result['predict01'] = np.where(result['predicted']> cutoff, 1, 0)
# 평가지표 저장하기.
acc.append(accuracy_score(result['actual'], result['predict01']))
rec.append(recall_score(result['actual'], result['predict01'], pos_label = 1))
prec.append(precision_score(result['actual'], result['predict01'], pos_label = 1))
- cut-off 값에 따른 Accuracy, Recall, Precision 값을 그래프로 확인
plt.figure(figsize = (12,8))
plt.plot(cutoff_values, acc, label = 'accuracy', color = 'darkred')
plt.plot(cutoff_values, rec, label = 'recall', color = 'blue')
plt.plot(cutoff_values, prec, label = 'precision', color = 'green')
# Accuracy를 최대화 해주는 cut off
max_acc_cut = round(cutoff_values[np.argmax(acc)],3)
max_acc = round(max(acc),3)
plt.axvline(max_acc_cut, color = 'r', linewidth = .7)
plt.text(max_acc_cut, .1, max_acc_cut, color = 'r')
plt.axhline(max_acc, color = 'r', linewidth = .7)
plt.text(max_acc_cut -.1, max_acc, max_acc, color = 'r')
plt.xlabel('cut-off values')
plt.legend()
plt.grid()
plt.show()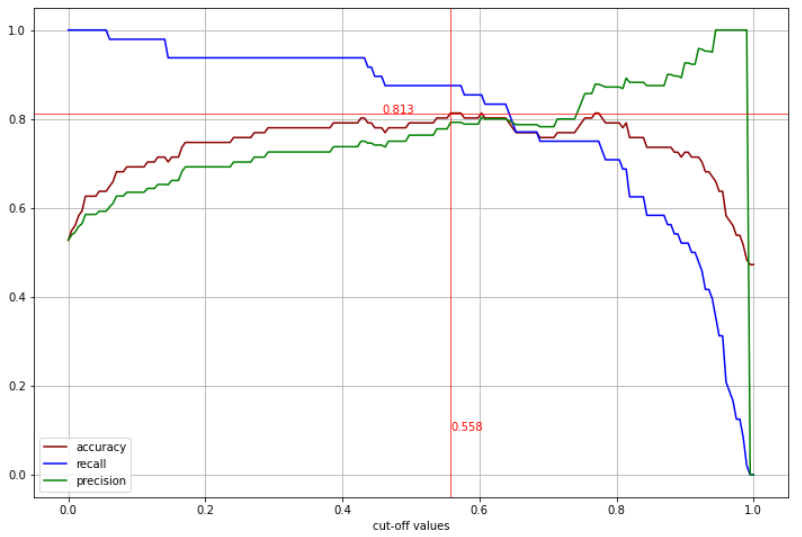
위의 그래프를 보면, recall과 precision이 서로 trade-off 관계라는 것을 알 수 있다.
가장 높은 accuracy값과 그때의 cut-off value도 그래프에 표시해주었다.
모델을 평가할 때 cutoff와 상관 없이 전반적인 평가를 하는 방법은, cutoff를 조금씩 조절하면서 성능의 curve를 그려서 비교하고 평가하는 것이다.
대표적으로 두가지 방법이 있는데
- AUROC : 민감도, 1-특이도 곡선 (실제값 관점에서 모델 성능)
- Precision-Recall Curve : Class 0 혹은 1 관점에서 모델의 성능
두가지 모두 curve의 아래 면적으로 비교하는 cut-off와 무관한 독립적인 모델 평가 지표이다.
이 중 Precision-Recall curve를 활용해보았다.
# precision - recall curve
plt.figure(figsize = (10,8))
plt.plot(rec, prec)
plt.xlabel('recall')
plt.ylabel('precesion')
plt.grid()
plt.show()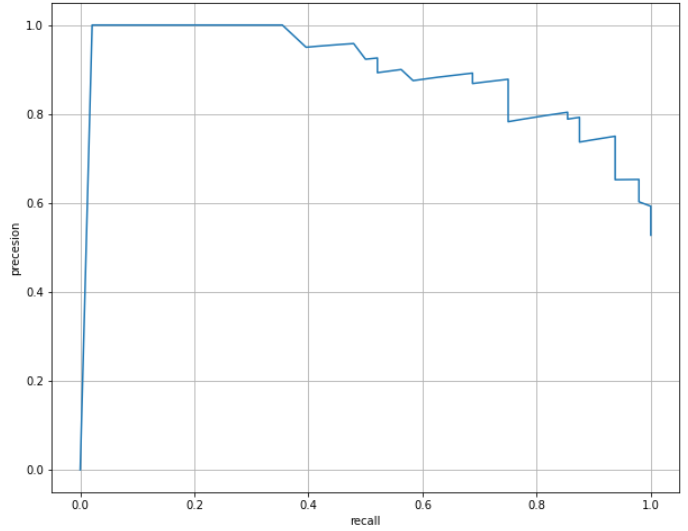
sklearn에서 제공하는 precision_recall_curve 함수를 사용하면 다양한 threshold값에 따른 precision-recall 쌍의 값을 구할 수 있다.
- precision_recall_curve( 실제값, 확률예측값 )
precision, recall, threshold = precision_recall_curve(y_val, result['predicted'])
plot_precision_recall_curve( 모델, x_val, y_val ) 로 precision-recall 그래프를 바로 그릴 수 있는데, 사이킷런 1.2 버전부터는 사용되지 않는 것 같다. from_predictions나 from_extimator를 사용하라고 한다.
참고 : https://scikit-learn.org/stable/modules/generated/sklearn.metrics.plot_precision_recall_curve.html
sklearn.metrics.plot_precision_recall_curve
scikit-learn.org
그래도 일단 plot_precision_recall_curve로 그려보면
# precision - recall curve
plt.figure(figsize = (12,8))
pr_curve = plot_precision_recall_curve(model, x_val, y_val, ax = plt.gca())
plt.show()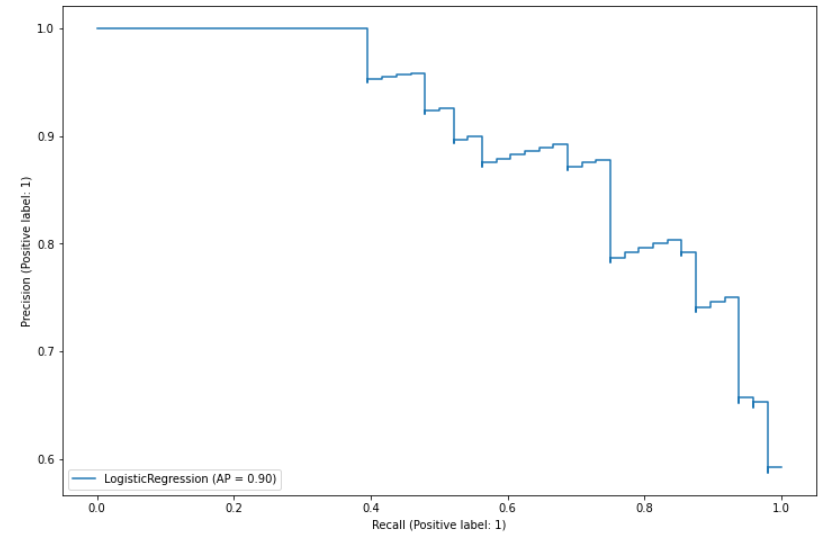
precision-recall 그래프를 확인할 수 있다.
plot_precision_recall_curve의 결과를 저장하고, .average_precision 속성을 불러오면 그래프 아래의 면적을 확인해볼 수 있다.
pr_curve.average_precision
# 0.9022013399245508
'인공지능 AI' 카테고리의 다른 글
| [ LightGBM ] (0) | 2022.09.11 |
|---|---|
| [ 정규화 : RobustScaler ] (0) | 2022.09.10 |
| [ Class Imbalance (클래스 불균형) ] (0) | 2022.09.10 |
| [ Ensemble(앙상블) - Stacking ] (0) | 2022.09.10 |
| [MAC] Google Colab(구글 코랩) 런타임 연결 끊김 방지하기 (0) | 2022.05.26 |