
Class Imbalance (클래스 불균형)
대부분의 비즈니스 상황에서 타겟 클래스의 불균형은 매우 흔하다.
예를 들어 제조 공정간 불량 예측을 수행하는 모델을 학습시킬 때,
데이터 중에는 정상 데이터가 불량보다 훨씬 많을 것이다.
머신러닝 알고리즘들은 보통 데이터가 클래스 내에서 고르게 분포되어있다고 가정하기 때문에,
다수의 클래스를 더 많이 예측하는 쪽으로 모델이 편향되는 경향이 있다.
즉, 소수의 클래스에서 오분류 비율이 높아질 수 있다는 것이다.
이러한 부분 때문에 클래스 불균형은 모델링을 할때 매우 문제가 될 수 있다.
극단적인 예시를 한번 살펴보면
실제값 314개의 데이터 중 0은 283개, 1은 31개인 데이터에 대해서 모델이 314개를 모두 0이라고 예측했다고 해보자
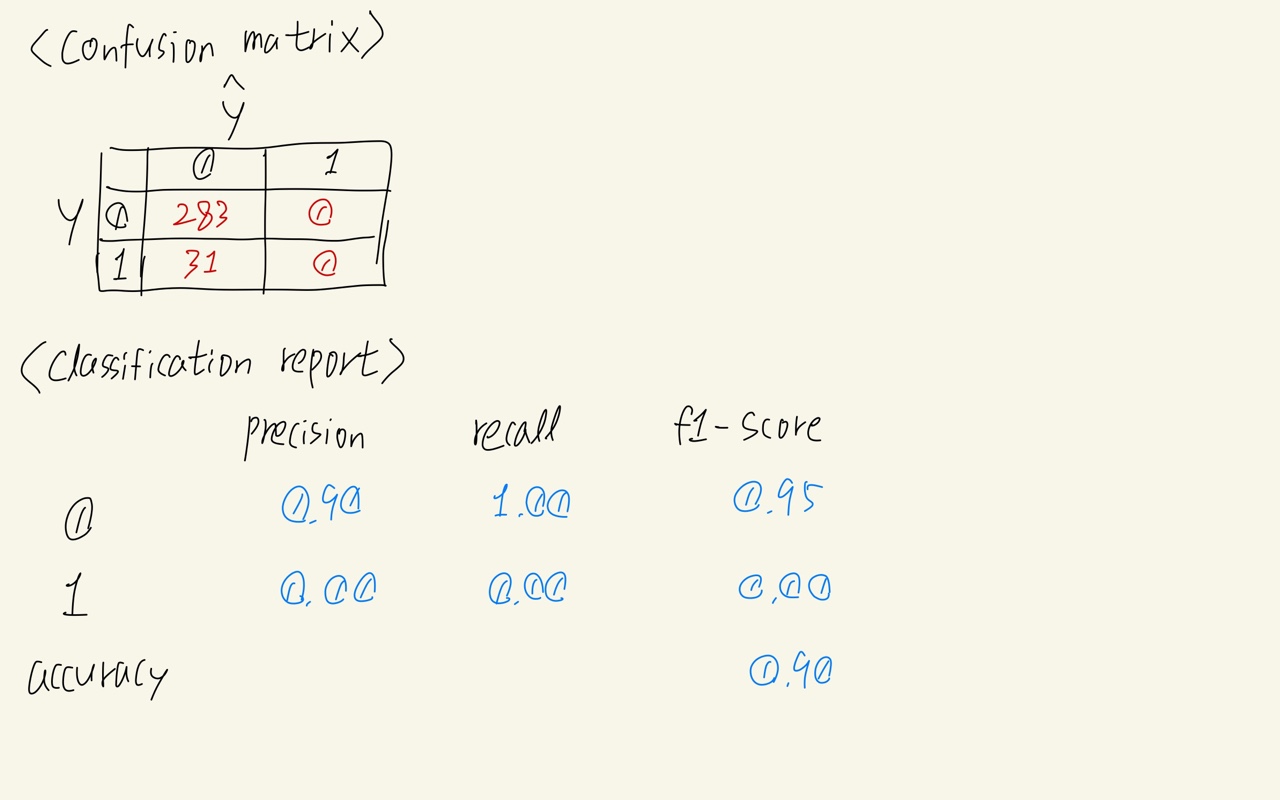
이 분류모델이 예측을 한 결과를 confusion matrix와 classification report로 확인해보았다.
이 모델이 예측한 모든 결과는 0이었다. 하지만 1인 데이터의 수가 훨씬 적은 클래스 불균형 상태이기 때문에
- 0에 대한 precision, recall, f2-score값은 매우 높은 값이 나왔다.
- 반면에 1에 대한 평가지표를 살펴보면 모두 0으로 형편없는 결과를 얻은 것을 볼 수 있다.
결과적으로 양이 훨씬 많던 0클래스는 정답을 많이 맞췄기 때문에 전반적인 모델의 accuracy가 높은 값이 나와서 이 모델을 그냥 사용해도 된다고 생각하게 될 수도 있다.
하지만 소수의 1의 결과를 감지해내는 것이 모델이 수행해야 하는 중요한 역할이기 때문에 이 모델은 사용하면 안된다.
Class Imbalances를 해결하기 위한 방법으로는 다음의 두가지가 있다.
- Resampling
- Class Weight 조정
참고로 이 방법들은 전반적인 성능을 높이기 위한 작업이 아니라, 소수 Class에 대한 성능을 높이기 위한 작업이라는 것을 알아두자.
소수 클래스에 대한 성능을 높이면 자연스럽게 다수 클래스에 대한 성능은 떨어질 수밖에 없을 것이다.
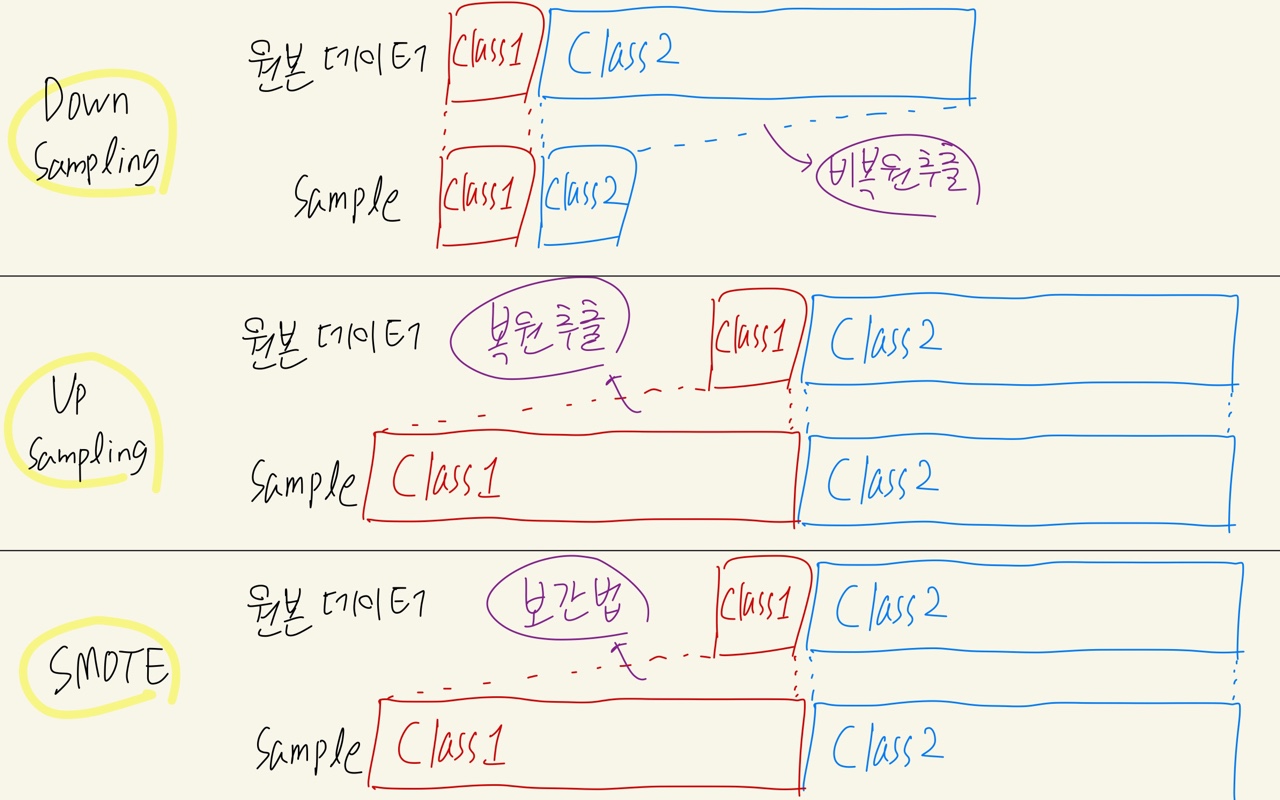
[ Resampling ]
- Down Sampling : 다수 Class의 데이터를 소수 Class 만큼 random sampling(비복원추출)
- Up Sampling : 소수 Class의 데이터를 다수 Class 수 만큼 random sampling(복원추출)
- SMOTE(Sythetic Minority Oversampling TEchnique) : 소수 샘플에 보간법(Interpolation)으로 새로운 데이터를 만들어냄
- resampling 필요 함수 불러오기
from imblearn.under_sampling import RandomUnderSampler
from imblearn.over_sampling import RandomOverSampler, SMOTE
- RandomUnderSampler() : Down Sampling 수행
# Down Sampling : 많은쪽 클래스를 적은쪽의 개수만큼 랜덤 샘플링
rus = RandomUnderSampler()
x_d, y_d = rus.fit_resample(x, y)스케일링 하는 것과 유사하다.
- RandomOverSampler() : Up Sampling 수행
# 적은쪽 클래스를 많은쪽의 개수만큼 랜덤하게 복원추출
ros = RandomOverSampler()
x_u, y_u = ros.fit_resample(x, y)
- SMOTE() : SMOTE Sampling 수행
# 적은쪽 클래스를 보간법을 사용해서 개수를 늘림
smote = SMOTE()
x_sm, y_sm = smote.fit_resample(x, y)
다음과 같이 생긴 불균형 데이터를 생성해준 뒤, SVM모델로 그냥 모델링을 수행해보고, Resampling된 데이터를 사용해서 모델링을 수행해본 뒤 비교해보았다.
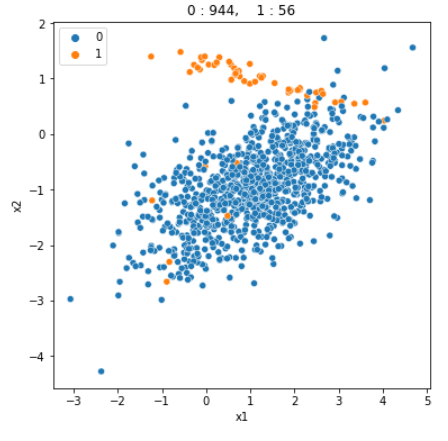
- 불균형 데이터 그대로 사용해서 모델링
# 불균형 데이터 그대로 모델링
model = SVC(kernel='linear')
model.fit(x, y)
pred = model.predict(x)
print(confusion_matrix(y, pred))
print('=' * 55)
print(classification_report(y, pred))SVC 모델이 분류한 결과는 다음과 같다.


- Down Sampling 수행한 데이터로 모델링
# Down Sampling
rus = RandomUnderSampler()
x_d, y_d = rus.fit_resample(x,y)

학습 결과
model_ds = SVC(kernel='linear')
model_ds.fit(x_d, y_d)
# 모델링 및 평가
pred_ds = model_ds.predict(x)
print(confusion_matrix(y, pred_ds))
print('=' * 60)
print(classification_report(y, pred_ds))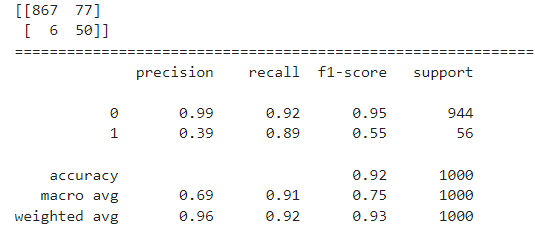

- SMOTE Sampling 수행한 데이터로 모델링
# SMOTE Sampling
smote = SMOTE()
x_sm, y_sm = smote.fit_resample(x,y)

학습 결과
model_sm = SVC(kernel='linear')
model_sm.fit(x_sm, y_sm)
# 모델링 및 평가
pred_sm = model_sm.predict(x)
print(confusion_matrix(y, pred_sm))
print('=' * 60)
print(classification_report(y, pred_sm))

[ Class Weight 조절 ]
Resampling 없이 클래스에 가중치를 부여하여 클래스 불균형 문제를 해결하는 방법이다.
학습하는 동안 알고리즘의 비용 함수에서 소수의 클래스에 더 많은 가중치를 부여하여 소수 클래스에 더 높은 패널티를 제공함으로써, 소수 클래스에 대한 오류를 줄이게 된다.
sklearn에서 제공되는 알고리즘들은 대부분 class_weight 라는 하이퍼파라미터를 제공하는데, 이를 사용해서 class weight를 조절할 수 있다.
- class_weight = 'None' : 기본값
- class_weight = 'balanced' : y_train의 class 비율을 역으로 적용
- class_weight = {0:0.2, 1:0.8} : 비율을 직접 지정. (비율의 합이 1이 되어야 함.)
'인공지능 AI' 카테고리의 다른 글
| [ LightGBM ] (0) | 2022.09.11 |
|---|---|
| [ 정규화 : RobustScaler ] (0) | 2022.09.10 |
| [ 분류를 위한 기준 (Cut-off Value) ] (0) | 2022.09.10 |
| [ Ensemble(앙상블) - Stacking ] (0) | 2022.09.10 |
| [MAC] Google Colab(구글 코랩) 런타임 연결 끊김 방지하기 (0) | 2022.05.26 |