
[ 배운 내용 ]
1. BatchNormalization(), Dropout()
2. Computer Vision
- Convolutional Neural Network (CNN)
3. CNN 코드 작성 실습
- Conv2d, MaxPool2D 사용
1. BatchNormalization, Droupout
BatchNormalization()
: 각 계층에 대해 평균과 표준편차를 0과 1이 되도록 만들어줌 (각 층의 활성화값을 정규분포로 적절하게 퍼뜨려준다.)
- Internal Covariate Shift 현상을 방지한다.
- 학습을 빠르게 진행할 수 있다.
- 초기값에 크게 의존하지 않게 된다.
- 오버피팅을 억제해준다.
Internal Covariate Shift
: 레이어를 거칠 때마다 분포의 변화가 심화되어서 차이가 도드라지는 현상 (epoch 별로 분포가 점점 극단적으로 되어 학습이 불안정하게 이루어지는 현상)

Internal covariate shift 현상을 방지하는 것이 주 목적인 만큼 애초에 BatchNormalization의 의도는
히든레이어에 대한 전처리 과정으로서 이전 계층 ==> BatchNormalization ==> activation 의 순서대로 동작이 이루어지도록 하는 것이었다.
하지만 막상 사용해보니 activation까지 거치고 나서 사용하는 것의 성능이 더 잘나와서
이전 계층(activation까지) ==> BatchNormalization 의 순서대로 사용해주게 되었다.
웬만하면 BatchNormalization을 수행한 결과가 더 좋게 나온다고 한다.
Dropout()
: 학습할때마다 지정된 양만큼의 노드들을 임의로 삭제한 채로 모델링 해본다. (몇몇 노드들이 없는 것처럼 간주)
- 오버피팅을 방지할 수 있다.
- 모델을 train set에만 너무 맞추지 않고 일반적으로 잘 적용될 수 있도록 해준다.
- 서로 다르게 생긴 뉴럴 네트워크를 사용하게 되기 때문에 앙상블과 비슷한 효과
[ BatchNormalization, Dropout 코드작성 ]
모델링 시 BatchNormalization()과 Droupout()을 사용하는 방법은 다른 계층들과 비슷하다.
둘 다 모델의 성능을 높이기 위한 보조 레이어다.
from tensorflow.keras.layers import Input, Dense, Flatten, BatchNormalization, Dropout- BatchNormalization() : 디폴트 값이 충분히 좋기 때문에 그대로 사용
- Droupout(0.2) : 20%의 노드들을 학습할 때마다 랜덤하게 제거하고 사용
## Functional
# 1. 세션 클리어
clear_session()
# 2. 레이어 연결
il = Input(shape=(28,28,1))
fl = Flatten()(il)
hl1 = Dense(512, activation='swish')(fl)
bl1 = BatchNormalization()(hl1)
hl2 = Dense(256, activation='swish')(bl1)
bl2 = BatchNormalization()(hl2)
hl3 = Dense(128, activation='swish')(bl2)
bl3 = BatchNormalization()(hl3)
dl = Dropout(0.2)(bl3) # 각 노드의 20%를 학습할 때마다 랜덤하게 제거하고 사용 (모델이 일반적으로 잘 적용되도록)
ol = Dense(10, activation='softmax')(dl)
# 3. 모델의 시작과 끝 선언
model = Model(il, ol)
# 4. 컴파일
model.compile(loss=keras.losses.categorical_crossentropy, metrics=['accuracy'], optimizer=keras.optimizers.Adam())
# 모델링 정보 확인
model.summary()2. Computer Vision
컴퓨터 비전(Computer Vision)이란 컴퓨터의 입장에서 세상을 어떻게 바라보는지 고민하는 분야이다.
컴퓨터 비전에서는 다음과 같은 문제들을 해결하고자 한다.
- Object Detection, Semantic Segmentation
- Image Classification
- Action Classification
- Captioning
Pixel(픽셀)
: 화면을 구성하는 가장 기본이 되는 단위
과거부부터 해서 컴퓨터에게
흑백의 간단한 이미지 해석을 시켜봄 -> '에지'를 이해시켜봄 -> '계층'을 이해시켜봄 -> 사물의 움직임을 이해시켜봄 ->사물의 스케일을 이해시켜봄 등의 과정을 거쳐서
2000년대에 들어서는 컴퓨터가 '특정 이미지 조각'을 가지고 분류할 수 있게 만들면서 Feature의 개념이 등장하게 되었다. 이로 인해 이미지 분류를 꽤 할 수 있게 되었지만 사람이 할 수 있는 수준에는 미치지 못했다고 한다.
미국의 컴퓨터 과학자인 페이페이 리 교수님께서는 "문제는 알고리즘이 아니라 데이터"라고 하면서 컴퓨터도 사람처럼 엄청나게 많은 양의 이미지를 봐오면서 학습을 하도록 해야 한다고 주장했다.
여기서 말하는 데이터 문제의 핵심은
- 데이터의 양이 많아야 한다.
- 데이터의 레이블링이 잘 되어있어야 한다. (지도학습을 위해)
이렇게 시작된 ImageNET 프로젝트를 통해 CNN (Convolutional Neural Network)가 등장하게 된다.
CNN은 이미지를 이미지답게(공간구조를 최대한 덜 훼손하면서) 다루어낸 최초의 알고리즘이다.
CNN의 등장을 기점으로 이미지 분류 성능이 대폭 향상되었다고 한다.
CNN (Convolutional Neural Network)
CNN의 동작 순서는 정말 간단하게 설명하면 아래와 같다.
- 이미지의 조각을 본다.
- 각 조각이 조합된 패턴을 본다.
- 점점 더 복잡한 조합의 패턴을 본다.
- 반응하는 여러 패턴의 조합을 가지고 이미지를 인식한다.
CNN에서는 다음의 2가지 핵심적인 Layer가 사용된다.
- Convolution Layer
- Pooling Layer
Convolution Layer
Concolution layer에서는 필터를 사용해서 이미지를 훑어준다. 한번씩 이동할 때마다 이전에 필터로 훑은 값들을 계산해서 이 값들이 모여 새로운 Feature map을 만들어준다. 하나의 Feature map을 만드는건 하나의 새로운 high-level feature를 만드는 것과 같다.
각 필터의 width,length는 직접 지정해주고, 만들어낼 feature map의 수도 직접 지정해준다. 만들려는 feature map의 개수만큼의 필터를 사용해서 훑게 된다.
필터의 depth같은 경우는 이전 레이어의 인풋의 depth를 그대로 따라가기 때문에 코드로 따로 표현하지는 않고, 필터 내부의 값들은 랜덤하게 생성된다.
필터가 한번에 이동하는 범위를 stride 값으로 지정해줄 수 있다. 이는 필터와 이전 계층의 인풋과 크기가 맞아 떨어져야 하지만 케라스에서는 사이즈가 안맞을 경우 한 줄을 덧대어서 보정해준다고 한다. stride를 어떻게 지정해주는지에 따라서 feature map의 크기가 달라질 것이다. 이로 인해 더 많은 특징을 담을지, 혹은 연산량을 줄이는 대신 더 함축된 특징들만을 담을지 등을 고민하게 된다.
하지만 이렇게 필터로 훑게 될 경우 각각의 픽셀이 공정하게 반영되지 못할 것이다. 외곽에 위치한 픽셀들은 중앙쪽에 있는 픽셀들에 비해서 필터에 포함되는 횟수가 적기 때문에 feature map에 덜 반영될 것이다.
이를 위해 zero padding을 사용해준다. zero padding을 해주면 이미지의 상하좌우로 0값이 들어있는 1픽셀씩 추가해준다. 이를 통해 다음의 효과를 얻을 수 있다.
- 외곽의 정보를 더 반영할 수 있다.
- 이전 feature map의 사이즈를 유지할 수 있다.
아래 그림을 보면 5x5 크기의 이미지가 있다. convolution layer에서 이 이미지를 3x3 크기의 필터를 가지고 stride=(1x1)을 주어서 가로세로 1칸씩 훑도록 해주었다. 그렇게 되면 (5-3+1)=3으로 3x3 크기의 새로운 feature map이 생성될 것이고, 새로운 feature map에는 필터와 이미지의 값들을 element-wise로 곱해서 모두 더해준 값들이 들어가게 된다.
(참고로 이미지가 흑백이라 5x5x1 사이즈였다면 depth값은 그대로 필터까지 전달돼서 필터 역시 3x3x1의 사이즈를 갖게 된다. 컬러의 경우에도 5x5x3 -> 3x3x3으로 될 것이고, 이후에 생성될 feature map의 depth(feature의 개수)에 필터를 적용하고 싶을 때도 동일하게 적용된다.)
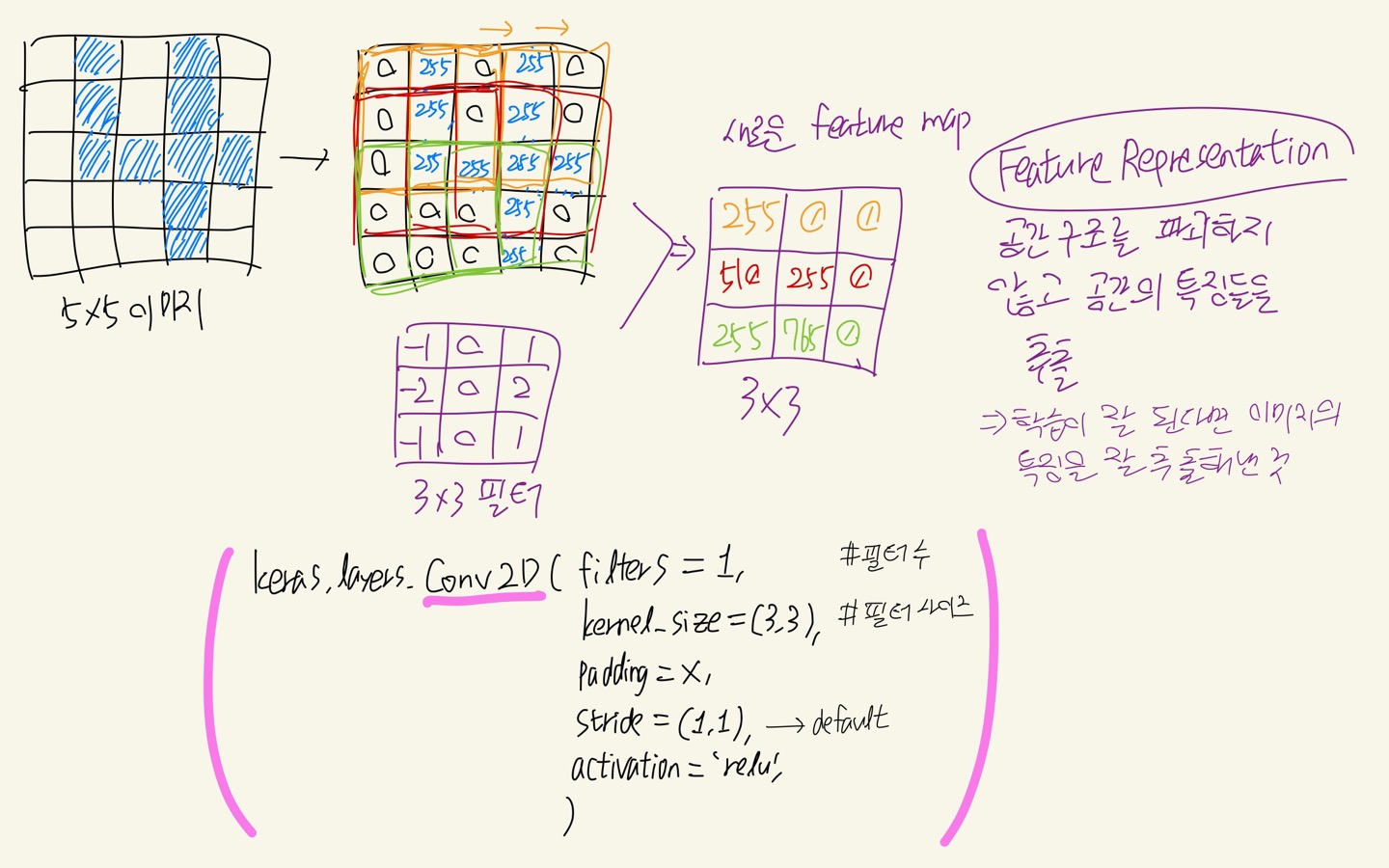
코드로는 tensorflow.keras.layers에서 Conv2D() 를 사용해준다.
Conv2D에서는 다음의 파라미터들로 위에서 설명한 내용들을 설정해줄 수 있다.
- filters : 필터 수
- kernel_size : 필터 사이즈
- padding : 그림에서는 설정해주지 않았지만 'same' 값을 준다면 이미지의 크기를 그대로 살리는 zero padding을 수행해준다.
- strides : 필터를 이동시킬 칸 단위 (디폴트 1x1)
Pooling Layer
Pooling layer의 역할은 이전 계층의 이미지 혹은 feature map의 가로세로 사이즈를 줄여서 연산량을 줄여주는 것을 주 목적으로 한다.
Convolution layer와 비슷하게 필터와 stride의 크기를 지정해주고(stride는 기본적으로 필터 크기를 따라감), 설정한 대로 필터가 훑으면서 훑을때마다의 필터 구간 내에서 가장 큰 값(혹은 평균값)만 뽑아온다.
이렇게 뽑아온 값들로 축소된 feature map을 만들어주는 것이 Pooling이다.
pooling의 종류에는 다음이 있다.
- Max Pooling : 가장 큰 값만 추출 (구간별로 영향력이 가장 큰 부분만 선택)
- Average Pooling : 평균값으로 추출 (영향력이 높은 값과 낮은 값을 골고루 반영)
아래와 같이 4x4 크기의 feature map에 필터의 크기는 (2x2), stride는 (2x2)를 주어서 Max Pooling을 적용해보았다.

tensorflow.keras.layers에서 MaxPool2D() 를 불러와서 사용 가능하고
다음의 파라미터들을 설정해준다.
- pool_size : 필터 크기
- strides : 필터를 이동시킬 단위
3.. Convolution Layer 코드 작성 실습
새로 배우는 내용을 사용할 때 필요한 코드 말고는 생략함
MNIST 손글씨 데이터 사용
- 함수 불러오기
from tensorflow.keras.layers import Input, Dense, Flatten, BatchNormalization, Dropout
이미지 크기 확인
28x28x1 크기의 흑백 이미지다.
print(train_x.shape, train_y.shape, test_x.shape, test_y.shape) # 28x28x1 사이즈 이미지
# (60000, 28, 28) (60000,) (10000, 28, 28) (10000,)
Convolution layer에서 사용하기 위해 x1의 채널을 추가해주어야 한다. (reshape 사용)
train_x.shape, test_x.shape
# ((60000, 28, 28), (10000, 28, 28))
_, h, w = train_x.shape
print(h, w)
# 28 28
## reshape
train_x = train_x.reshape(train_x.shape[0], h, w, 1)
test_x = test_x.reshape(test_x.shape[0], h, w, 1)
print(train_x.shape, train_y.shape, test_x.shape, test_y.shape)
(60000, 28, 28, 1) (60000,) (10000, 28, 28, 1) (10000,)
아래의 이유들로 인해 0~1사이의 값을 갖도록 이미지에 Min-Max Scaling을 수행해주었다.
- 학습을 빠르게 하기 위해
- local minima에 빠지지 않도록
max_num = train_x.max()
min_num = train_x.min()
train_x = (train_x - min_num) / (max_num - min_num)
test_x = (test_x - min_num) / (max_num - min_num)
- 모델링
## Sequential API
## 1. 세션 클리어
keras.backend.clear_session()
## 2. 모델 선언
model = keras.models.Sequential()
## 3. 레이어 쌓기
model.add( layers.Input(shape=(28, 28, 1)))
# Convolution layer
model.add( layers.Conv2D(filters=16, padding='same',
kernel_size=(3, 3),
activation='relu') )
# Pooling Layer (Max Pooling)
model.add( layers.MaxPool2D(pool_size=(2, 2)) )
model.add( layers.Conv2D(filters=32,
kernel_size=(3, 3),
activation='relu') )
model.add( layers.Flatten() )
model.add( layers.Dense(64, activation='relu') )
model.add( layers.Dense(10, activation='softmax'))
## 4. 컴파일
model.compile(loss=keras.losses.sparse_categorical_crossentropy,
optimizer='adam',
metrics=['accuracy'])
## 모델링 정보 확인
model.summary()
학습시켜서 결과를 확인해보니 이전의 평범한 fully connected neural network 구조를 사용했을 때보다 훨씬 좋은 성능이 나오는 것을 볼 수 있다.
pred_train = model.predict(train_x)
pred_test = model.predict(test_x)
single_pred_train = pred_train.argmax(axis=1)
single_pred_test = pred_test.argmax(axis=1)
logi_train_accuracy = accuracy_score(train_y, single_pred_train)
logi_test_accuracy = accuracy_score(test_y, single_pred_test)
print('CNN')
print('트레이닝 정확도 : {:.2f}%'.format(logi_train_accuracy*100))
print('테스트 정확도 : {:.2f}%'.format(logi_test_accuracy*100))
# CNN
# 트레이닝 정확도 : 99.25%
# 테스트 정확도 : 98.73%'KT AIVLE School' 카테고리의 다른 글
| (10주차 - 22.09.22-23) 시각지능딥러닝3 - 커스텀 이미지 데이터 Detection하기 + Annotation (0) | 2022.09.22 |
|---|---|
| (10주차 - 22.09.20~21) 시각지능딥러닝2 - Object Detection (YOLO) (0) | 2022.09.22 |
| (9주차 - 22.09.16) 딥러닝4 - Connection (0) | 2022.09.18 |
| (9주차 - 22.09.15) 딥러닝3 - 이미지(비정형)데이터 분류 (ANN 방식) (0) | 2022.09.16 |
| (9주차 - 22.09.14) 딥러닝2 - 히든레이어 (0) | 2022.09.15 |