
[ 배운 내용 ]
1. 머신러닝 - 딥러닝 차이?
2. 이미지 데이터(비정형 데이터) 분류 문제
- MNIST 손글씨 데이터
- MNIST 패션 데이터
- CIFAR-10 데이터
1. 머신러닝 - 딥러닝 차이?
우선 다음 그림을 먼저 보자

머신러닝으로 문제를 해결할 때에는 항상 주어진 데이터가 모델의 성능에 가장 많은 영향을 끼친다. 때문에 주어진 데이터를 최대한으로 활용해야 하며, 문제를 해결하기에 도움이 될 만한 feature를 사람이 직접 만드는 feature engineering이 필수적이다. 이를 위해서는 도메인 지식도 필수적일 것이다.
이렇게 도메인 지식도 습득하고 머리를 쥐어짜서 새로운 feature를 만들어서 모델링을 하게 되면 힘든건 둘째 치고, 사람이 찾지 못하는 여러 요인들로 인해 좋은 성능이 잘 나오지 않을 때도 많다.
좋은 Feature들이란 다음의 조건들을 만족해주어야 한다.
- Error를 줄여줌 (예측 성능이 좋다.)
- 모델을 설명하기에 용이함
- 학습하기에 충분한 양이있어야 함
하지만 우리가 힘들게 Feature Engineering을 통해 만든 Feature는 모델을 설명하기엔 좋아 보이지만 성능이 안좋을 수 있고, 학습하기에 충분한 양이 없을 수도 있다.
그에 반해서 Artificial Neural Network 구조를 기반으로 하는 딥러닝에서는 아래 그림과 같이 히든레이어의 개수(Feature Learning의 수준)와 노드의 개수(High level Feature 개수)로 우리는 구조만 만들어주면 유용한 feature를 모델이 알아서 만들고 학습해준다.

그렇다고 무조건 딥러닝이 머신러닝보다 뛰어나다는 것은 아니다.
Tabular Data(정형데이터)의 경우에는 머신러닝이 딥러닝보다 성능이 좋거나 비슷하다고 한다.
참고로 Tabular data란 우리가 흔히 알고 있는 행과 열로 된 정형 데이터를 말하며, 이미 잘 정제된 데이터를 뜻한다. 이런 데이터는 보통 양이 어마어마하게 많지 않고, faeture engineering도 사람이 할만하다.
그에 반해 이미지, 텍스트와 같은 비정형 데이터들은 유용한 feature를 사람이 직접 정의하는 것이 사실상 불가능에 가깝다. 이런 경우에는 스스로 유용한 feature를 생성해주는 딥러닝이 머신러닝보다 좋다.
다양한 데이터를 다루기 위해서 딥러닝은 반드시 공부할 필요가 있으며, 머신러닝과 딥러닝 중 어떤 방식이 더 좋은지는 데이터를 보고 우리가 판단할 수 있어야 한다.
2. 이미지 데이터 분류 문제
MNIST 손글씨 데이터
Artificial Neural Network 구조의 딥러닝 모델로 MNIST 손글씨 분류 문제를 수행해보았다.
train_x.shape, train_y.shape, test_x.shape, test_y.shape
((60000, 28, 28), (60000,), (10000, 28, 28), (10000,))
데이터는 (28,28) 크기의 이미지 데이터고 총 60000개가 있다.
Fully connected 뉴럴 네트워크 구조에서는 입력을 1차원으로 받기 때문에 입력 데이터를 1차원으로 만들어주어야 한다.
입력 데이터를 1차원으로 펴주는 방법은 2가지가 있다.
- reshape() 수행해주기
- Flatten() 레이어 추가
- reshape() 사용해서 입력 데이터 1차원으로 펼쳐주기
train_x = train_x.reshape([train_x.shape[0],-1])
test_x = test_x.reshape([test_x.shape[0],-1])
train_x.shape
# (60000, 784)
[ Min-Max Scaling ]
사이킷런에서 제공하는 MinMaxScaler를 사용한 스케일링은 2차원 구조의 데이터에서는 사용할 수 없다.
지금은 데이터를 1차원으로 바꿔주어서 적용은 가능하지만 수동으로 스케일링을 해보았다.
max_n, min_n = train_x.max(), train_x.min() # min,max값은 train 기준으로
max_n, min_n
# (255, 0)
train_x = (train_x - min_n) / (max_n - min_n)
test_x = (test_x - min_n) / (max_n - min_n)
train_x.max(), train_x.min()
# (1.0, 0.0)그리고 이 데이터는 모든 픽셀에서 min,max값이 동일하게 0,255인 이미지 데이터라서 그냥 위와 같이 element-wise 방식으로 연산하는 것이 가능한 것이다.
하지만 iris 데이터 같이 정형화된 tabular 데이터에서는 각 feature별로 값의 분포가 많은 차이를 보이기 때문에 feature별로 각각 min-max처리를 해주는 MinMaxScaler를 꼭 사용해주는 것이 좋다.
[ One-hot Encoding ]
- set() 함수로 학습 데이터가 갖고있는 고유한 값을 확인해볼 수 있다. set()으로 교유값을 뽑아내고 그 길이값을 사용해서 to_categorical()함수의 파라미터로 넣어줄 수 있다.
from tensorflow.keras.utils import to_categorical
set(train_y) # train_y가 갖고있는 값 확인
# {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
len_y = len(set(train_y))
# one-hot encoding
train_y = to_categorical(train_y, len_y)
test_y = to_categorical(test_y, len_y)
train_y.shape
# (60000, 10)- 데이터가 넘파이 어레이로 되어 있을 경우에는 set()함수가 안먹기 때문에 np.unique()로 확인해주자
# 넘파이 어레이일 경우
class_num = len(np.unique(train_y))
[ 모델링 - Sequential 방식 ]
# Sequential API
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 모델 선언
model = keras.models.Sequential()
# 3. 레이어 조립 : .add()
model.add(keras.layers.Input(shape=(train_x.shape[1])) )
model.add(keras.layers.Dense(10, activation='softmax') )
# 4. 컴파일
model.compile(loss=keras.losses.categorical_crossentropy, metrics=['accuracy'],
optimizer=keras.optimizers.Adam(0.01)) # Adam(0.01) -> learning_rate=0.01 (디폴트는 0.001)
model.summary()
[ Early Stopping ]
Early Stopping
: 과적합을 방지하기 위해 사용하는 방법으로, 학습 시에 지속적으로 성능을 모니터링 하면서 지정된 수준만큼 학습이 되지 않고 있다고 판단되면 학습을 멈추게 해주는 기능
- monitor : 모니터링 대상
- min_delta : 모델이 개선되었다고 판단할 기준 (min_delta보다 큰 값으로 개선되지 않는다면 개선되지 않은 것으로 간주)
- patience : 성능이 개선되지 않는 것을 몇 번이나 허용할 지
- restore_best_weights : 학습이 멈췄을 때 최적의 가중치 사용
from tensorflow.keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss', # 관측 대상
min_delta=0, # 0 : 최소한 성능이 나빠지지만 않으면 괜찮음
patience=5, # 최고 성능에서 성능이 개선되지 않는걸 몇번이나 참을지
verbose=1, # early stopping이 어디서 되는지 확인하기 위해
restore_best_weights=True # 학습이 멈췄을 때, 최적의 가중치로 돌려줌 (반드시 True로 주자)
)
[ 모델 학습 ]
모델을 학습하는 것은 에러가 줄어드는 방향으로 가중치를 업데이트 하는 과정이다.
- validation_split : 학습 직전에 train set을 지정한 비율만큼 쪼개서 validation set으로 사용한다.
- callback : 체크포인트 확인이나 Early Stopping 등 여러 기능을 추가해줄 수 있다.
- batch_size : 아래 코드에는 사용하지 않았지만, 한번 업데이트 될 때 반영할 데이터의 숫자를 의미한다. (디폴트 32)
batch_size만큼 데이터를 끊어서 학습하는 방식을 Mini Batch 라고 한다.
1 epoch의 의미는 모든 데이터를 1번 학습했다는 것을 의미한다.
1 epoch 동안 많은 양의 학습 데이터를 사용해서 학습이 이루어질 텐데 몇만개의 데이터를 한번에 학습하는 것은 OOM(Out Of Memory) 문제를 일으킨다. 이 문제를 피하기 위해 1 epoch 당 데이터를 지정된 batch_size만큼 쪼개서 학습을 해주는 것이다.
model.fit(train_x, train_y, epochs=50, verbose=1,
validation_split=0.2,
callbacks=[es],
)
학습 과정을 살펴보면 1 Epoch 당 1500번의 미니 배치 학습이 이루어진다는 것을 알 수 있다.
학습 데이터 60,000 ==> train : 48,000 / val : 12,000 ==> 48,000 / 32(batch size) = 1,500
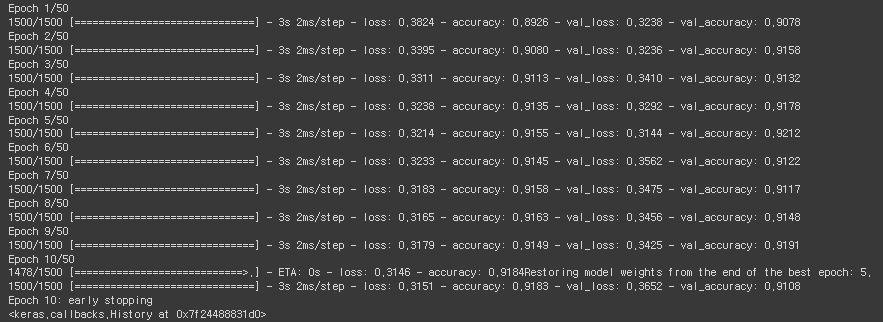
Early Stopping으로 학습을 중간에 끊어주었고, val_loss가 가장 작게 나온 모델을 자동으로 선택해준다.
- 학습이 이루어질 때 train set에 맞춰서 계속 학습이 되다 보니 loss와 accuracy 값은 계속해서 좋아진다.
- 하지만 val_loss와 val_accuracy값은 계속 좋아지기만 하지 않는 것을 볼 수 있는데, 이런 경우를 과적합이라고 볼 수도 있기 때문에 Early Stopping을 설정해주는 것이 좋다.
[ 히든레이어 포함한 모델링 - Sequential방식 ]
각각 노드가 256개인 히든레이어를 3개 추가한 모델링도 진행해보았다. (Sequential)
keras.backend.clear_session()
model = keras.models.Sequential()
model.add(keras.layers.Input(shape=(train_x.shape[1])) )
model.add(keras.layers.Dense(256, activation='relu') ) # Input으로부터 새롭게 추출된 feature 256
model.add(keras.layers.Dense(256, activation='relu') ) # 첫번째 히든레이어로부터 새롭게 추출된 256개의 feature
model.add(keras.layers.Dense(256, activation='relu') )
model.add(keras.layers.Dense(10, activation='softmax') )
model.compile(loss=keras.losses.categorical_crossentropy, metrics=['accuracy'],
optimizer='adam')
model.summary()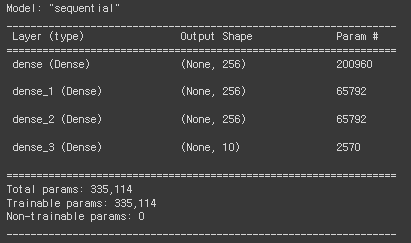
Fashion MNIST 데이터
Artificial Neural Network 구조의 딥러닝 모델로 Fashion MNIST 의류 데이터 분류 문제를 수행해보았다.
기존의 MNIST 손글씨 데이터는 너무 쉽고, 많이 사용된 데다 현대의 컴퓨터 비전 과제에 적절한 데이터는 아니어서 새로 등장한 데이터라고 한다. (지금은 얘도 그냥 그런듯)
데이터를 확인해보면 구조 자체는 MNIST 손글씨 데이터와 동일하다는 것을 확인해볼 수 있다.
print("x_train shape:", x_train.shape, "y_train shape:", y_train.shape)
# x_train shape: (60000, 28, 28) y_train shape: (60000,)이런 식으로 생긴 데이터가 티셔츠, 트라우저, 풀오버, 드레스 등의 총 10개의 카테고리로 라벨링 되어있다.

이번에는 reshape()가 아니라 Flatten() 계층을 추가해주어서 데이터의 차원을 바꿔줄 것이다.
[ Min-Max Scaling ]
print(x_train.max(), x_test.min())
max_n, min_n = x_train.max(), x_train.min()
x_train = (x_train - min_n) / (max_n - min_n)
x_test = (x_test - min_n) / (max_n - min_n)
print(x_train.max(), x_train.min())
# 255 0
# 1.0 0.0
[ One-hot Encoding ]
from tensorflow.keras.utils import to_categorical
# 고유값 확인
set(y_train), set(y_test)
# ({0, 1, 2, 3, 4, 5, 6, 7, 8, 9}, {0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
# One-hot Encoding
class_num = len(set(y_train))
y_train = to_categorical(y_train, class_num)
y_test = to_categorical(y_test, class_num)
y_train.shape, y_test.shape
# ((60000, 10), (10000, 10))
[ 모델링 - Functional 방식 ]
인풋 레이어 다음에 Flatten() 레이어를 연결해주기만 하면 인풋 데이터가 1차원으로 펴진다.
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 레이어 연결
il = keras.layers.Input(shape=(28,28)) # shape=(x_train.shape[1], x_train.shape[2])
fl = keras.layers.Flatten()(il)
hl1 = keras.layers.Dense(256, activation='relu')(fl)
hl2 = keras.layers.Dense(128, activation='relu')(hl1)
hl3 = keras.layers.Dense(64, activation='relu')(hl2)
ol = keras.layers.Dense(10, activation='softmax')(hl3)
# 3. 모델의 시작과 끝 지정
model = keras.models.Model(il,ol)
# 4. 컴파일
model.compile(loss=keras.losses.categorical_crossentropy, metrics=['accuracy'],
optimizer=keras.optimizers.Adam())
#### 모델 요약
model.summary()
model.summary()로 모델링 정보를 확인해보면 인풋 레이어 다음에 flatten 레이어가 위치해있고, Param 개수가 0인걸 보면 아무 학습도 이루어지지 않는 계층이라는 것을 알 수 있다. Flatten()은 그냥 이전 계층의 차원만 바꿔주는 계층이라고 보면 된다.
CIFAR-10 데이터
토론토대학에서 제공해주는 데이터로 비행기, 자동차, 고양이, 새, 말 등 10가지의 사물과 동물의 카테고리로 분류되어 있는 이미지 데이터로 이전에 사용한 손글씨, 패션 데이터보다 어려운 데이터이다.
데이터는 32x32 크기의 2차원 이미지인데 RGB 3가지로 이루어진 이미지들이 하나씩 있기 때문에 3차원의 구조를 갖는다.
즉 컬러 이미지이고, 기존의 데이터들보다 크기 때문에 학습시간이 더 오래 걸린다. (구글코랩 GPU 사용했음)
print(train_x.shape, train_y.shape, test_x.shape, test_y.shape) # 2차원 이미지 데이터가 RGB 3가지로
# (50000, 32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)
[ Min-Max Scaling ]
max_n, min_n = train_x.max(), train_x.min()
max_n, min_n
# (255, 0)
# 스케일링
train_x = (train_x - min_n) / (max_n - min_n)
test_x = (test_x - min_n) / (max_n - min_n)
train_x.max(), train_x.min()
# (1.0, 0.0)
[ One-hot Encoding]
train_y가 넘파이 어레이 형태라서 seT()을 사용하면 오류가 날 것이다.
np.unique()를 사용해서 고유값을 꺼내주었다.
from tensorflow.keras.utils import to_categorical
class_num = len(np.unique(train_y))
train_y = to_categorical(train_y, class_num)
test_y = to_categorical(test_y, class_num)
train_y.shape, test_y.shape
# ((50000, 10), (10000, 10))
train_x.shape, train_y.shape, test_x.shape, test_y.shape
# ((50000, 32, 32, 3), (50000, 10), (10000, 32, 32, 3), (10000, 10))
[ 모델링 - Sequential 방식 ]
기존에 작성하던 코드들은 계속 keras. 으로 케라스로 일일이 접근해서 메서드들을 꺼내왔다.
이번에는 코드를 좀 간결하게 작성하고자 필요한 메서드들은 모두 미리 임포트 해놓고 코드를 작성해였다.
- 메서드 불러오기
from tensorflow.keras.backend import clear_session
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Dense, Flatten
from tensorflow.keras.losses import categorical_crossentropy
from tensorflow.keras.optimizers import Adam
- 모델링
Flatten()으로 인풋 데이터를 펼쳐주었고, 히든 레이어를 4개 추가해주었다.
# 1. 세션 클리어
clear_session()
# 2. 모델 선언
model = Sequential()
# 3. 레이어 조립 512, 512, 256, 128
model.add(Input(shape=(32,32,3)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
# 4. 컴파일
model.compile(loss=categorical_crossentropy, metrics=['accuracy'], optimizer=Adam())
model.summary()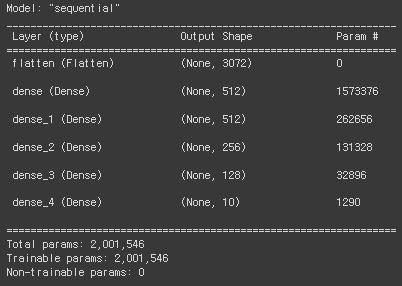
데이터의 크기가 커졌기 때문에 학습 파라미터가 엄청나게 많아졌다.
[ Early Stopping ]
from tensorflow.keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss',
min_delta=0,
patience=5,
verbose=1,
restore_best_weights=True)
[ 모델 학습 ]
history = model.fit(train_x, train_y, epochs=50, verbose=1,
validation_split=0.2, callbacks=[es])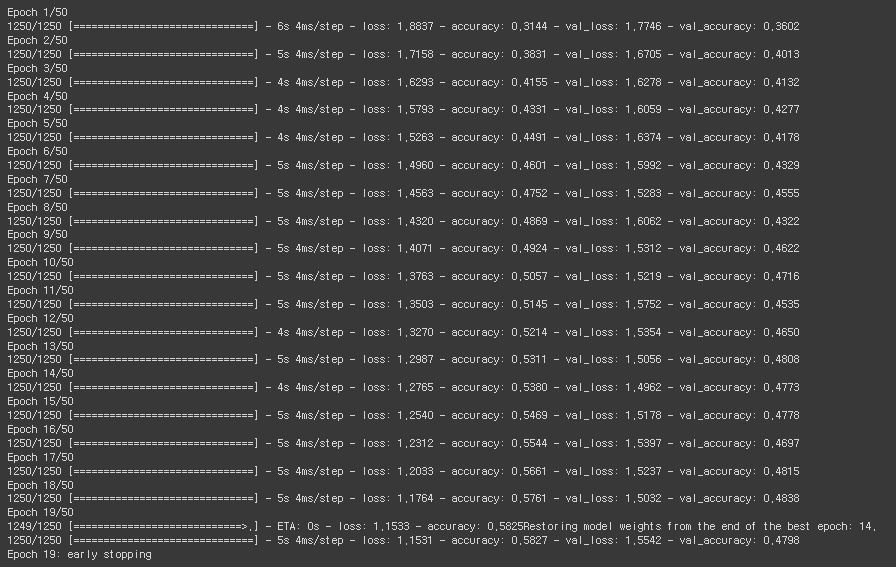
MNIST 손글씨와 패션 데이터에 비해서 성능이 훨씬 잘 안나오는 것을 볼 수 있다.
epoch 별 loss와 accuracy값을 각각 시각화해서 확인해보았다.


validation 성능이 어느 정도 선에서 멈춰 있는 것이 관측된다.
히든 레이어만 쌓는 고전적인 ANN(Artificial Neural Network) 방식으로는 테스트정확도가 50%를 넘지 않는다고 한다. loss값도 어느정도 아래로는 더이상 떨어지지 않는다.
히든 레이어를 아무리 추가해도 그대로이고, 이는 이 방식에 한계가 있다는 것을 의미한다.
reshape나 Flatten 과 같은 방식으로 기존 이미지의 구조를 파괴시켜서 학습시키는 방식에는 한계가 있다.
기존 의미지의 구조를 유지시켜서 공간의 구조와 특징을 살린 채로 특징을 찾아 학습하는 방식이 필요한데 이 방식의 모델이 바로 CNN(Convolutional Neural Network)이다.
CNN은 이후 시각지능 딥러닝 시간에 배울 예정이다.
'KT AIVLE School' 카테고리의 다른 글
| (10주차 - 22.09.19) 시각지능딥러닝1 - BatchNormalization, Dropout, Conputer Vision (CNN) (0) | 2022.09.20 |
|---|---|
| (9주차 - 22.09.16) 딥러닝4 - Connection (0) | 2022.09.18 |
| (9주차 - 22.09.14) 딥러닝2 - 히든레이어 (0) | 2022.09.15 |
| (9주차 - 22.09.13) 딥러닝1 - Tensorflow + Keras (선형회귀, 로지스틱회귀, 멀티클래스분류) (0) | 2022.09.13 |
| (7주차 - 22.09.05 ~ 22.09.06) AI모델 해석/평가 (0) | 2022.09.05 |