
[ 배운 내용 ]
1. Hidden Layer (은닉층)
- Hidden Layer를 추가하여 모델링 : 선형회귀, 이진분류, 멀티클래스분류
- MNIST 분류 실습
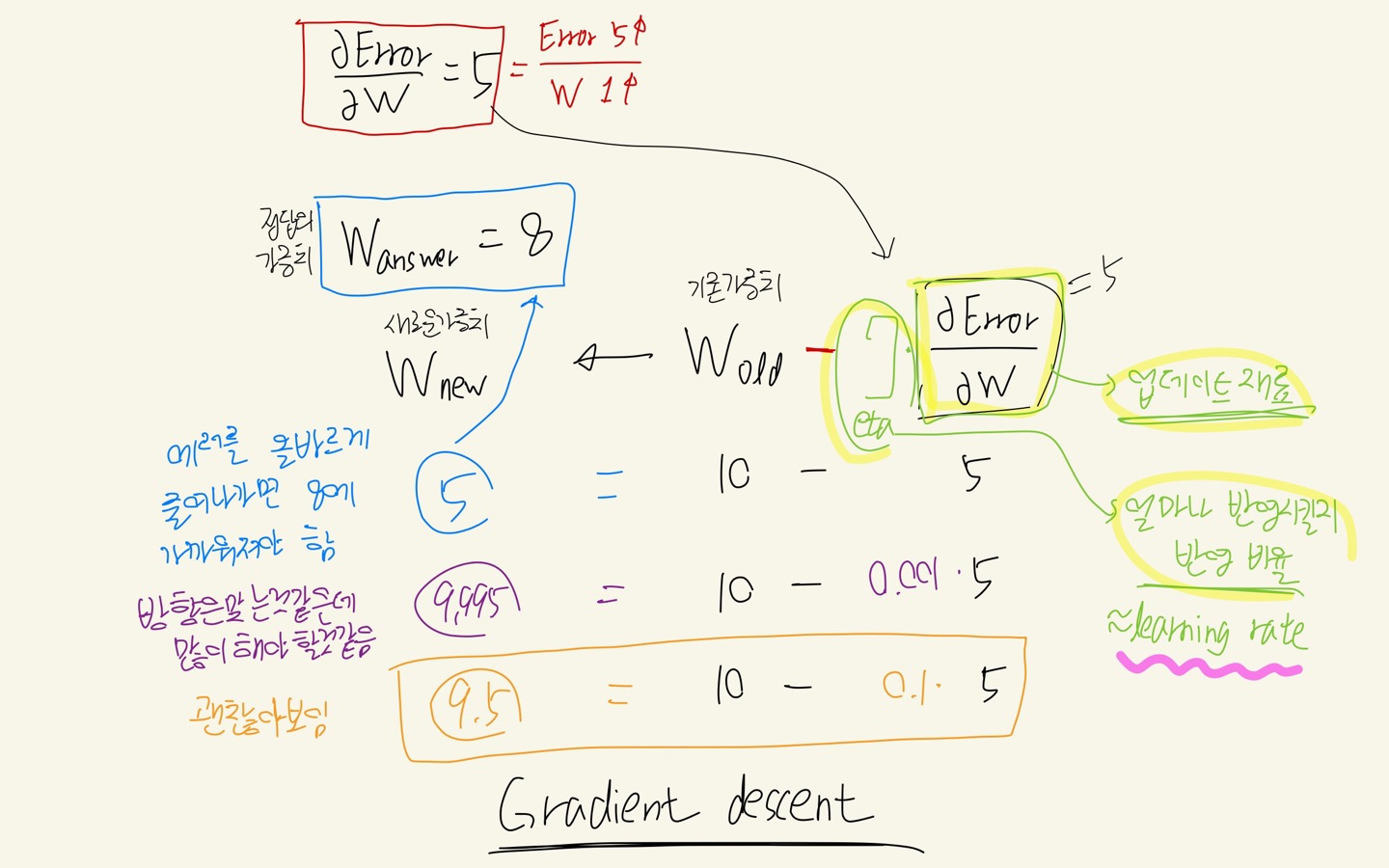
딥러닝의 지도학습에서 "학습"이란?
-> Error(오차)를 줄여나가는 방향으로 W(가중치)를 업데이트 해주는 것 (update : 기존의 것을 고쳐줌 = 개선)
===> 이 과정을 [ Gradient descent ] 라고 한다.
Gradient descent 진행 시 기존의 가중치를 우리가 원하는 최적의 가중치로 점점 업데이트하게 된다.
이 때, 가중치 대비 에러값의 변화량에 learning rate를 곱한 값을 기존의 가중치에서 빼며 업데이트 하는데, 이 learning rate 값이 적절해야 우리가 원하는 가중치를 향해 점점 갱신될 것이다.
- learning rate 값이 너무 크면 우리가 원하는 가중치를 한참 지나가버릴 수 있고
- learning rate 값이 너무 작아도 업데이트 속도가 너무 느릴 수 있기 때문에
적절한 값을 지정해줄 수 있어야 한다.
Hidden Layer
만약 아래 그림과 같은 글씨 데이터가 주어질 경우, 컴퓨터는 사람처럼 딱 보고 구분할 수가 없기 때문에 데이터로부터 feature를 추출해야 한다.
기존의 뉴럴 네트워크 구조에서 Hidden Layer(은닉층)라고 하는 중간 계층을 추가해줌으로써 이전 계층과 비교했을 때, 더 high level의 feature를 만들어줄 수 있다.
우리가 직접 feature를 만들었다기보단 성능에 유용한 feature를 컴퓨터(모델)이 알아서 만들어줬다고 생각하면 되겠다.

은닉층의 노드들이 바로 이전 계층 대비 high level의 feature들이고,
이렇게 연결된 것(feature, input)으로부터 기존에 없던 새로운 특징을 추출하는 것을 Feature Representation이라고 한다.
그렇다면 우리가 알고 직접 feature를 만드는 것도 아닌데 히든 레이어와 노드의 개수를 어떻게 조절해야 하는지에 대해 아래와 같은 의문이 생길 것이다.
- 히든 레이어를 몇개 추가해 줄지?
- 히든 레이어 안에 노드를 몇개 추가해 줄지?
이에 대한 대답은 다음과 같다.
--> 성능 향상이 더이상 되지 않을 때까지 늘려보면 된다!
딥러닝의 최고 권위자 중 한 분이신 몬트리올 대학교의 Yoshua Bengio 교수님이 하신 대답이라고 한다.
히든레이어와 노드에 따른 모델 성능의 여러 케이스가 있을텐데 아래 대답들과 같이 해석해볼 수 있다.
Q1. 만약 히든 레이어의 노드를 더 추가했더니 성능이 더 올랐다면?
A1. 성능에 유용한 feature가 추가된 거라고 볼 수 있다.
Q2. 만약 히든 레이어의 노드를 하나 삭제했더니 모델의 성능이 그대로 유지되었다면?
A2. feature가 이미 충분한 상태 (상대적으로 이전 계층보다 고수준이긴 하지만 불필요한 feature였던것)
Q3. 히든 레이어를 새로 추가했더니 성능이 더 올랐다면?
A3. 이 모델에 좀 더 고수준의 feature가 더 필요했던 것
히든 레이어를 추가하여 모델링
- 히든 레이어를 추가할 때는 Dense(노드개수)로 계층을 더 추가해주면 된다.
- activation함수로는 relu를 지정해준다. (activation='relu')
- relu : 0보다 작은 값은 0으로 / 0보다 큰 값은 살리는 함수
보스턴 집값 데이터 선형회귀문제를 Sequential 방식으로 모델링 해보자
- input feature : 13개
- output feature : 1개
- hidden layer : 2개
- 각 hidden layer의 노드 수 : 32개
x.shape, y.shape
# ((506, 13), (506,))
- 모델링
## 모델링 - Sequential 선형회귀
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 모델링
model = keras.models.Sequential()
# 3. 레이어 쌓기
model.add(keras.layers.Input(shape=(13,)))
model.add(keras.layers.Dense(32,activation='relu')) # 히든레이어1
model.add(keras.layers.Dense(32,activation='relu')) # 히든레이어2
model.add(keras.layers.Dense(1))
# 4. 컴파일
model.compile(loss='mse', optimizer='adam')
# 모델링 정보 확인
# (13+1) * 32 -> 448
# (32+1) * 32 -> 1056
# 32+1 -> 33
model.summary()
# Model: "sequential"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# dense (Dense) (None, 32) 448
#
# dense_1 (Dense) (None, 32) 1056
#
# dense_2 (Dense) (None, 1) 33
#
# =================================================================
# Total params: 1,537
# Trainable params: 1,537
# Non-trainable params: 0
# _________________________________________________________________.Dense() 안에 노드의 수를 지정해주고 activation='relu'로 지정해준 것 외에는 모두 기존의 모델링과 동일하다.
model.summary() 로 모델링 정보를 확인해 볼 수 있는데,
- Sequential 방식의 경우 Input layer는 다음 계층에 합쳐진 채로 확인이 가능하다.
- Functional 방식은 모든 계층 각각 확인 가능
- Param수로 각 계층의 파라미터 수를 볼 수 있다. 각 계층별로 인풋이 되는 노드의 수는 bias(편향)값도 고려해서 1개가 더 계산된다.
히든 레이어를 추가한 모델은 epochs 등 다른 조건을 모두 동일하게 했을 때, 기본 모델보다 더 금방 학습하고, 더 좋은 성능이 나오는 것을 확인해볼 수 있다.
[ cancer 데이터 이진분류 문제 Functional 방식으로 모델링 ]
x.shape, y.shape
# ((569, 30), (569,))## 모델링 - Functional 이진분류
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 레이어 연결
il = keras.layers.Input(shape=(30,))
hl1 = keras.layers.Dense(32,activation='relu')(il)
hl2 = keras.layers.Dense(32,activation='relu')(hl1)
ol = keras.layers.Dense(1,activation='sigmoid')(hl2)
# 3. 모델의 시작과 끝 지정
model = keras.models.Model(il,ol)
# 4. 컴파일
model.compile(loss=keras.losses.binary_crossentropy, metrics=['accuracy'], optimizer='adam')
# 모델 정보 확인
model.summary()
Model: "model"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# input_1 (InputLayer) [(None, 30)] 0
#
# dense (Dense) (None, 32) 992
#
# dense_1 (Dense) (None, 32) 1056
#
# dense_2 (Dense) (None, 1) 33
#
# =================================================================
# Total params: 2,081
# Trainable params: 2,081
# Non-trainable params: 0
# _________________________________________________________________
[ iris 데이터 멀티클래스분류 문제 Functional 방식으로 모델링 ]
test 데이터셋의 역할
- 새로운 데이터가 아니지만, 새롭게 들어오는 데이터의 역할을 기대
So, test데이터는 떼어놓고 들여다보지도 말자
- 한꺼번에 전처리 -> train,test분리 ==> 이렇게 하지 말것!!
- train, test를 분리 -> 각자 전처리 ==> 이렇게 하자
- 분리한 이후에 train셋에 적용한 전처리 규칙을 동일하게 적용해줘야 함
이번에는 train과 test 데이터도 스플릿 해준 뒤 모델링해주었는데, 우리의 목표는 기존에 모르던 데이터가 들어와도 모델은 잘 작동하도록 하는 것이다. 때문에 test 데이터는 모델이 아예 모르는 데이터라고 간주해야 한다.
그래서 target데이터의 one-hot encoding은 물론이고 그 밖의 데이터 전처리를 해줄 때 train과 나눠서 독립적으로 수행해주어야 한다.
train셋과 test셋을 먼저 분리해주고, 이후에 train데이터셋에 적용한 전처리 방식을 test에 동일하게 수행해주자.
어차피 전처리 할 거 그냥 맨처음에 하면 안되나? 라고 생각하면 안된다!!
x.shape, y.shape
# ((150, 4), (150,))
## train set / test set 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size=0.2, random_state=2022)
x_train.shape, y_train.shape
# ((120, 4), (120,))
# 고유원소 확인
print(np.unique(y_train))
print(np.unique(y_test))
# [0 1 2]
# [0 1 2]
- 전처리(one-hot encoding)
from tensorflow.keras.utils import to_categorical
class_num = len(np.unique(y_train))
y_train = to_categorical(y_train, class_num)
y_test = to_categorical(y_test, class_num)
x_train.shape, y_train.shape
# ((120, 4), (120, 3))
- 모델링
## 모델링 - Functional 멀티클래스 분류
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 모델 연결
il = keras.layers.Input(shape=(4,))
hl1 = keras.layers.Dense(32, activation='relu')(il)
hl2 = keras.layers.Dense(32, activation='relu')(hl1)
ol = keras.layers.Dense(3, activation='softmax')(hl2)
# 3. 모델의 시작과 끝 지정
model = keras.models.Model(il, ol)
# 4. 컴파일
model.compile(loss=keras.losses.categorical_crossentropy, metrics=['accuracy'], optimizer='adam')
model.summary()
'KT AIVLE School' 카테고리의 다른 글
| (9주차 - 22.09.16) 딥러닝4 - Connection (0) | 2022.09.18 |
|---|---|
| (9주차 - 22.09.15) 딥러닝3 - 이미지(비정형)데이터 분류 (ANN 방식) (0) | 2022.09.16 |
| (9주차 - 22.09.13) 딥러닝1 - Tensorflow + Keras (선형회귀, 로지스틱회귀, 멀티클래스분류) (0) | 2022.09.13 |
| (7주차 - 22.09.05 ~ 22.09.06) AI모델 해석/평가 (0) | 2022.09.05 |
| (6주차 - 22.08.29) 머신러닝6 - 시계열 분석 (0) | 2022.08.29 |