
[ 배운 내용 ]
1. AI모델 해석
- 모델에 대한 설명
(1) Feature Importance (변수 중요도)
- Tree 기반 모델의 변수 중요도
- Permutaion Feature Importance
(2) Partial Dependence Plots (PDP)
(3) SHAP
1. AI모델 해석
AI 모델의 해석 및 평가는 비즈니스 상황에서 고객과 소통을 하기 위해 반드시 필요하다.
고객은 AI 전문가에게 다음의 2가지 질문을 던질 수 있다.
- 모델이 왜 그렇게 예측했나요?
- 모델은 비즈니스 문제를 해결할 수 있을까요?
고객의 요청을 받고 우리가 만든 AI 모델의 성능을 고객이 믿으려면
모델의 성능을 고객이 이해할 수 있도록 설명이 가능해야 한다.
간단한 예시를 들어 보자
우리는 한 병원의 요청을 받아서 환자의 감기 여부를 판단하는 AI 모델을 만들었다.
모델의 성능이 좋은 것은 병원 측에서도 확인을 했다. 하지만 병원 측에서 이 모델이 환자의 감기 여부를 판단한 근거를 궁금해 할 경우, 이를 Accuracy, Recall, Precision, F1_score 등의 모델의 성능지표로 설명하는 것은 병원 입장에서 이해하기 어려울 것이다.
그래서 우리는 "환자가 체온이 높았고, 두통과 피로감이 있었기 때문에 저희 모델은 감기 환자라고 판단했습니다." 와 같은 형식으로 설명을 할 수 있어야 한다.
하지만 이 근거가 될 변수들이 고객의 입장에서도 납득이 될 만한 변수들이어야 한다.
만약 모델이 감기 환자라고 판단한 환자들의 대부분이 남성이었기 때문에 "환자가 남성이면 저희 모델은 감기 환자라고 판단합니다." 라는 식의 설명은 병원 측에서 납득하기 힘들 것이다.
따라서 무조건 맞추기만 하는 성능만 좋은 모델이 아니라 모델이 결과를 맞췄을지라도, 그렇게 판단한 근거를 고객이 믿을 수 있도록 설명이 가능한 모델을 우리는 만들어야 한다.
[ 모델에 대한 설명 ]
모델의 해석(Interpretability)은 Input에 대해 모델이 왜 그런 output을 예측했는가? (어떤 변수가 모델에서 가장 중요한가?) 를 설명하는 영역이고,
모델의 설명(Explainability)은 모델의 해석을 포함하면서, 추가로 투명성에 대한 요구도 하는 영역이다. 모델이 어떻게 학습되는지 단계별로 설명이 가능해야 하고 최근의 추세는 설명과 해석을 혼용해서 사용한다고 한다.
Linear Regression이나 Decision Tree 등의 알고리즘들은 우리가 설명하기가 매우 쉽지만 대체로 성능이 낮고,
Neural Network, Gradient Boosting, Random Forest 등의 알고리즘들은 성능이 좋은 대신 설명이 어렵다.
모델에 대한 설명은 다음과 같이 크게 3가지로 나눌 수 있다.
- 모델 전체에서 어떤 Feature가 중요할까? (Feature Importance)
- 특정 Feature값의 변화에 따라 예측 값은 어떻게 달라질까? (Partial Dependence Plot)
- 이 데이터(분석단위)는 왜 그러한 결과로 예측되었을까? (Shapley Additive Explanation)
여기서 1번과 2번은 전체 데이터에에 대한 설명이고
3번은 개별 데이터에 대한 설명이다.
※ 참고로 위의 설명들은 모두 feature와 예측 결과 간의 관계를 설명하는 것이기 때문에 당연히 모델의 성능이 좋다는 것이 전제로 깔려 있어야 한다.
때문에 모델의 튜닝(최적화)이 반드시 선행되어야 한다.
1. Feature Importance (변수 중요도)
모델이 결과를 예측하는데에 있어서 중요한 요인을 찾기 위해 변수 중요도 (Feature Importance)를 확인할 수 있다.
변수 중요도
- 알고리즘 별 내부 규칙에 의해, 예측에 대한 변수 별 영향도를 측정한 값
- 성능이 낮은 모델에서의 변수 중요도는 의미 없음
[ Tree 기반 모델의 변수 중요도(Feature Importance) ]
Tree기반 알고리즘들은 모델에서 Feature Importance를 기본적으로 제공한다.
- Decision Tree
- Rancom Forest
- XGBoost
- Decision Tree의 변수중요도 MDI (Mean Decrease Immpurity)
: 트리 전체에 대해서 feature별로 Information Gain의 (가중)평균을 계산한 값
(Information gain : 지니 불순도가 감소하는 정도)
- Random Forest의 변수 중요도 (Mean Decrease GINI)
: 개별 트리들의 각각의 MDI로부터, feature별 Importance의 평균을 계산한다.
- XGBoost의 변수 중요도
:
XGBoost의 변수 중요도를 계산하는 방법은 3가지가 존재한다.
- weight : 모델 전체에서 해당 feature가 split될 때 사용된 횟수의 합
- gain : feature별 평균 information gain (total_gain : feature별 information gain의 총 합)
- cover : feature가 split할 때 샘플 수의 평균 (total_cover : 샘플수의 총 합)
의사결정트리와 랜덤 포레스트에서는 model.feature_importances_ 로 변수 중요도를 확인할 수 있다.
model.feature_importances_
XGBoost에서는 model.feature_importances_ 말고도 plot_importance() 함수로 로 변수 중요도를 확인할 수 있다.
model.feature_importances_ 의 기본값은 gain이고,
plot_importance() 의 기본값은 weight이다. (importance_type 옵션을 지정해주면 gain과 cover도 확인 가능)
- plot_importance( )로 weight 확인
# importance_type='weight' (디폴트)
plot_importance(model)
plt.show()
- plot_importance( )로 gain 확인 (importance_type='gain')
# importance_type='gain' or 'total_gain'
plot_importance(model, importance_type='gain')
plt.show()
- plot_importance( )로 cover확인 (importance_type='cover')
# importance_type='cover' or 'total_cover'
plot_importance(model, importance_type='cover')
plt.show()
변수 중요도를 확인만 하는 것에서 끝내지 않고, 이렇게 확인한 변수 중요도를 바탕으로 각 변수들에 대해 이변량 분석을 진행했던 내용과 연관지어서 생각할 수 있어야 한다.
[ Permutaion Feature Importance ]
Premutation Feature Importance는 알고리즘과 상관 없이 변수 중요도를 파악할 수 있는 방법이다. (트리 기반 모델이 아니어도 사용 가능)
순서가 부여된 임의의 집합을 다른 순서로 뒤섞는 연산인 Premutation(순열)에 기반한 중요도로,
Feature 하나의 데이터를 무작위로 섞을 때, model의 score가 얼마나 감소되는지로 계산하는 값이다.
많이 감소될수록 중요한 변수라고 볼 수 있다.
알고리즘 식은 아래와 같다.

특정 Feature j에 대해서, 여러 번(K번)의 시도만큼 섞은 뒤 Score를 계산한 값들의 평균과 기존 Score값의 차이값이다.
score값은
- 회귀 : R2_score
- 분류 : Accuracy
의 값을 베이스로 계산된다.
하지만 알고리즘 구조 상, 특정 변수 하나에 대해서만 섞기 때문에 다중 공산성이 있는 변수가 존재할 때, 한 변수를 섞어도 관련된 다른 변수는 그대로 있기 때문에 Score가 별로 줄어들지 않을 수 있다는 단점이 있다.
permutation_importance( model, x,y, n_repeats=반복횟수 ) 를 사용해서 PFI값을 구할 수 있다.
아래 코드는 회귀 문제를 해결하는 SVM 모델의 PFI값을 구하는 예시 코드다.
scoring 옵션은 디폴트로 accuracy가 지정되어 있기 때문에 회귀 모델의 r2스코어로 지정해준다.
pfi1 = permutation_importance(model1, x_val_s, y_val, n_repeats=10, scoring='r2', random_state=2022)
pfi
# {'importances_mean': array([0.00945374, 0.02086725, 0.03294957, 0.03386631, 0.02895424,
# 0.14430705, 0.05740539, 0.01810863, 0.02795648, 0.06606279,
# 0.07908538, 0.01881995, 0.24118307]),
# 'importances_std': array([0.00267741, 0.00728268, 0.00678155, 0.01320997, 0.00993524,
# 0.01427471, 0.01680534, 0.01403577, 0.01069404, 0.01817568,
# 0.01402084, 0.01418209, 0.02658648]),
# 'importances': array([[0.01202894, 0.0107116 , 0.00956138, 0.01383913, 0.00721868,
# 0.00671367, 0.0131682 , 0.00643447, 0.00687128, 0.00799003],
# [0.01532828, 0.02365336, 0.031247 , 0.01905323, 0.03024437,
# 0.01534974, 0.02420276, 0.0057787 , 0.01862319, 0.02519188],
# [0.01920832, 0.03288757, 0.03588737, 0.03716216, 0.03562646,
# 0.03493756, 0.03327672, 0.02338953, 0.0322704 , 0.04484963],
# [0.04604279, 0.02896597, 0.02650305, 0.06144869, 0.03828285,
# 0.02357206, 0.03553383, 0.00886427, 0.03593179, 0.03351783],
# [0.02155195, 0.02763862, 0.02381862, 0.04908277, 0.04350943,
# 0.01898032, 0.0253759 , 0.0174404 , 0.03515601, 0.02698836],
# [0.14934697, 0.14898562, 0.13328107, 0.13896236, 0.12637877,
# 0.16767923, 0.16166089, 0.15589054, 0.12170238, 0.13918266],
# [0.04145372, 0.06286162, 0.07553061, 0.08115248, 0.05905493,
# 0.03770048, 0.05865293, 0.02669361, 0.07500178, 0.05595176],
# [0.00577686, 0.0067193 , 0.01801397, 0.02357895, 0.05238462,
# 0.00363296, 0.00710871, 0.02852383, 0.02236743, 0.01297963],
# [0.01190827, 0.02067969, 0.02779514, 0.04551504, 0.03792619,
# 0.03976666, 0.01932715, 0.01725966, 0.02294811, 0.03643893],
# [0.04464871, 0.06331303, 0.06304896, 0.10061329, 0.07051806,
# 0.05531058, 0.06907357, 0.0339514 , 0.07431967, 0.08583063],
# [0.09220518, 0.05880734, 0.10171822, 0.08531476, 0.06025342,
# 0.06062406, 0.08927534, 0.08197305, 0.08355597, 0.07712646],
# [0.01132557, 0.01673283, 0.00119207, 0.01134066, 0.01020677,
# 0.01051101, 0.01447341, 0.04289672, 0.04768539, 0.02183508],
# [0.23150373, 0.23251305, 0.2386813 , 0.28489797, 0.20398572,
# 0.22588963, 0.28164085, 0.21759432, 0.27090865, 0.22421553]])}
Output (딕셔너리 형식)
- importances : feature별 반복횟수만큼 계산된 Score
- importances_mean : 변수별 평균
- importances_sdt : 변수별 표준편차
permutaion_importance 결과를 시각화해서 각 feature 별 score값의 분포를 확인해보자
# kdeplot(밀도함수그래프)로 확인
plt.figure(figsize = (10,8))
for i,vars in enumerate(list(x)) :
sns.kdeplot(pfi1.importances[i], label = vars)
plt.grid()
plt.legend()
plt.show()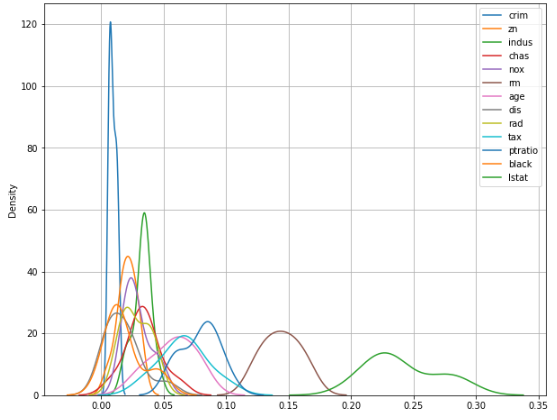
# boxplot으로 확인
sorted_idx = pfi1.importances_mean.argsort()
plt.figure(figsize = (10, 8))
plt.boxplot(pfi1.importances[sorted_idx].T, vert=False, labels=x.columns[sorted_idx])
plt.axvline(0, color = 'r')
plt.grid()
plt.show()
※ PFI값이 마이너스로 나오는 경우는 섞은 경우의 성능이 더 잘 나오는 경우이다.
이런 경우 해당 변수는 빼주는게 더 나을 수도 있다.
패턴에 방해가 되는 변수이기 때문에 해당 변수를 때고 모델링 해볼 필요도 있다.
2. Partial Dependence Plots (PDP)
관심 feature의 값이 변할 때, 모델에 미치는 영향을 시각화 해서 확인할 수 있는 방법이다.
모든 데이터를 지정된 feature의 모든 값으로만 채워보면서 결과를 확인해보고 해당 feature가 모델에 미치는 영향을 시각화 해준다.
아래의 그림은 보스턴 집값 데이터셋에서 상위 3건의 데이터에 대해서만 rm(방 수)에 따른 예측 결과를 PDP를 그려서 분석해 본 결과다.
PDP를 그릴 때는 plot_partial_dependence( model, features=[ 'rm' ], X=x_train, kind='both') 과 같은 식으로 그려볼 수 있다.
- model : 이미 만든 모델
- features : 분석할 대상 feature (리스트 형태로 넣어주어야 함)
- X : 데이터셋(x)
- kind : 'both' -> 개별 instance와 average값 함께 그리기
var = 'rm'
temp = x_train.head(3).copy() # 상위 3건에 대해서만
plt.rcParams['figure.figsize'] = 10, 6
plot_partial_dependence(model, features = [var], X = temp, kind = 'both') # features 옵션은 리스트 형태로 넣어주어야 함
plt.grid()
plt.show()

이 경우에 각 행의 rm값은 6.172, 7.470, 6.272 이다.
PDP에서는 위의 3행의 데이터의 모든 rm값들을 6.172, 7.740, 6.272로 각각 다 넣어봤을 때의 결과를 시각화해준다.
흐린 선은 각각의 인스턴스(분석단위)가 6.172, 7.740, 6.272의 값일 때마다의 예측 결과이고, 굵은 선은 각 인스턴스의 예측 결과의 평균을 나타낸 것이다.
이제 전체 데이터에 대해 PDP를 그려보자
plt.rcParams['figure.figsize'] = 12, 8
plot_partial_dependence(model,
features = [var],
X = x_train,
kind = 'both')
plt.grid()
plt.show()
위의 그림을 보면 방 수(rm)가 6.7~7.0 혹은 7.4~7.5 로 변하는 구간에서는 예측값인 집값(rm)이 급격히 상승하는 것을 볼 수 있다.
이런 식의 해석을 통해 우리는 고객이 이해하기 쉬운 방향으로 우리의 모델을 설명할 수 있다.
[ 두 Feature와 예측결과와의 관계 ]
두개의 feature와 예측결과와의 관계도 시각화하여 확인할 수 있다.
feature옵션에
- 두개의 변수를 리스트 형태로 넣어주면 각각의 PDP를 그려주고
- 두개의 변수를 튜플 형태로 넣어주면 한꺼번에 각 변수를 x,y축으로 한 예측 결과를 그려준다.
- 각각의 PDP 확인
# 두개의 feature를 리스트 형태로
plot_partial_dependence(model, features = ['rm','lstat'], X = x_train)
plt.show()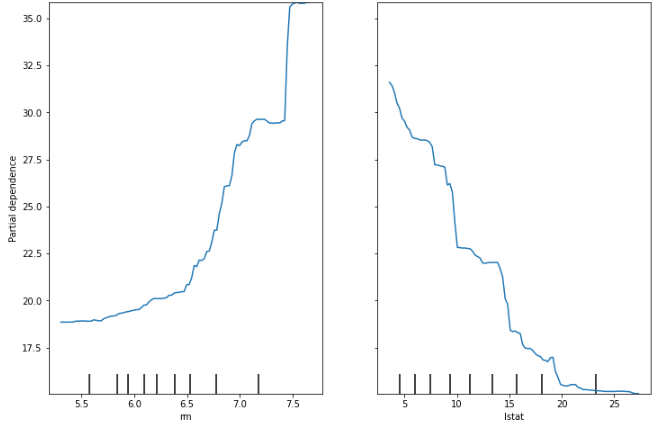
- 한꺼번에 확인
# 두개의 feature를 튜플 형태로
plot_partial_dependence(model, features = [('rm','lstat')], X = x_train)
plt.show()
지금까지 배운 내용들을 조합하여 다음과 같은 프로세스로 진행하는 것을 생각해 볼 수 있다.
- 문제를 해결하기 위해 다양한 알고리즘으로 모델을 만들고 성능을 평가한다. (튜닝)
- 변수 중요도를 확인한다. (트리모델 or Permutation Feature Importance)
- 선정된 모델에 대해 주요 변수의 값에 따른 예측 값 변화를 분석한다.
3. SHAP (SHapley Additive exPlanations)
비즈니스 상황에서 고객들은 모델에 대한 질문 뿐만 아니라, 해당 모델로 예측한 각 데이터에 대해서 왜 이러한 예측값이 나왔는지에 대해서도 질문할 수 있다.
이를 설명해 줄 수 있는 값이 Shapley value이다.
- Shapley value : 데이터의 각 분석단위의 모든 가능한 조합에서, 하나의 feature에 대한 평균 기여도를 계산한 값
하나의 데이터(분석단위)는 각 feature들이 특정 값을 갖고 있을 것이다. 이 feature 중에서 하나의 feature를 값 그대로 고정시킨 채, 다른 feature들의 가능한 모든 조합들의 경우에 대해서, 대상 feature가 있을 때와 없을 때의 예측값의 차이들을 구하고, 이 차이들의 가중평균을 구한 값이 해당 feature의 Shap value이다.
말이 좀 어려워서 그림으로 설명하자면
아파트 집값을 예측하는 모델이 있다고 해보자.
- Y : 집값
- X : 공원근처여부, 면적, 층, 반려동물허용여부
로 구성된 데이터셋을 사용한 모델이
- 공원근처여부 : 1
- 면적 : 50m^2
- 층 : 2층
- 반려동물허용여부 : x
의 값을 갖는 아파트의 가격을 30만 유로로 예측했다고 하자.
이 아파트 데이터에 대한 예측값에서 '반려동물허용여부' feature의 기여도를 알기 위해 '반려동물허용여부'의 값은 그대로 고정시킨 채로 나머지 feature들의 조합으로 총 8개의 조합을 얻어냈다.
그다음 각 조합별로 '반려동물허용여부' feature를 포함했을 때와 포함하지 않았을 때의 데이터를 모델이 예측한 결과의 차이들을 구해준 뒤, 이 차이들의 가중평균을 구한 값이 Shap value이다.

Shap value를 확인할 때는 각 머신러닝 알고리즘 별로 다른 함수를 사용한다.
- Tree기반 알고리즘 : TreeExplainer
- Deep Learning(딥러닝) : DeepExplainer
- SVM : KernelExplainer
- 그 외 일반 알고리즘 : Explainer
Shapley value를 코드로 직접 확인해보자
아래 예시는 랜덤포레스트 모델을 사용했고, 기본적으로 shapley value를 확인하는 절차는 다음과 같다.
- 모델 생성(학습)
- 생성된 모델로 Explainer를 만들고,
- 특정 데이터셋에 대해 shapley value를 추출
- 원하는 데이터 시각화
import shap
# 모델 학습
model1 = RandomForestRegressor()
model1.fit(x_train, y_train)
# Explainer를 만들고 x_train 데이터셋에 대해 Shapley value를 추출
explainer1 = shap.TreeExplainer(model1)
shap_values1 = explainer1.shap_values(x_train)
# x_train과 x_train에 대한 shapley value의 크기는 동일하다.
x_train.shape, shap_values1.shape
- x_train의 첫번째 행의 데이터와 그 데이터의 shap value 확인
x_train.iloc[0:1,:]
pd.DataFrame(shap_values1[0:1, :], columns = list(x_train))
- 모델의 기대값 확인 (예측값의 평균)
explainer1.expected_value
# array([21.79474505])
- 특정 데이터에서 feature 별 기여도 시각화
- shap.force_plot( 전체평균, shapley_values, input ) 로 시각화 가능하다.
shap.initjs() # javascript 시각화 라이브러리 --> colab에서는 모든 셀에 포함시켜야 함.(아나콘다에서는 한번만 실행해줘도 됨)
# force_plot(전체평균, shapley_values, input)
shap.force_plot(explainer1.expected_value, shap_values1[0, :], x_train.iloc[0,:])
force_plot으로 시각화한 결과를 통해 전체 평균을 중심으로 예측된 값에 어떠한 영향을 주었는지 변수별 확인이 가능하다.
이 때 상승요인과 하락요인이 있는데, 상승요인은 예측값을 높이는 요인, 하락요인은 예측값을 낮추는 요인이다.
- base value(21.79) : 기대값
- 진한 글씨(20.03) : 예측값
- 붉은색 변수 : 상승요인
- 푸른색 변수 : 하락요인
기대되는 예측값 base value에 대해 예측값(20.03)이 나오게 된 데에 있어서 영향을 끼친 요인들을 확인해볼 수 있다.
- 상승 요인 : crim, tax, ptratio, nox, age
- 하락 요인 : rm, dis, lstat, indus
다시 한 번 Shapley value를 정리하자면
예측값과 전체 평균과의 차이에 각 faeture가 얼마나 기여했는지 계산한 값이라고 할 수 있다.
- 전체 변수에 대한 shap vaue를 시각화 : shap.summary_plot(shap_value, input)
shap_values1 = explainer1.shap_values(x_train)
shap.summary_plot(shap_values1, x_train)
'KT AIVLE School' 카테고리의 다른 글
| (9주차 - 22.09.14) 딥러닝2 - 히든레이어 (0) | 2022.09.15 |
|---|---|
| (9주차 - 22.09.13) 딥러닝1 - Tensorflow + Keras (선형회귀, 로지스틱회귀, 멀티클래스분류) (0) | 2022.09.13 |
| (6주차 - 22.08.29) 머신러닝6 - 시계열 분석 (0) | 2022.08.29 |
| (5주차 - 22.08.26) 머신러닝5 - 비지도학습 (0) | 2022.08.26 |
| (5주차 - 22.08.25) 머신러닝4 - 모델 성능 향상, 앙상블 (0) | 2022.08.26 |