
[ 배운 내용 ]
1. Tensorflow + Keras 2.x 버전 코드로 구현
(1) 선형회귀
- Sequential API 방식 모델링
- Functional API 방식 모델링
(2) 로지스틱회귀 (이진분류)
- Sequential API 방식 모델링
- Functional API 방식 모델링
(3) 멀티클래스 분류 (iris 데이터)
- Sequential API 방식 모델링
- Functional API 방식 모델링
Tensorflow & Keras 2.x
Keras
: Tensorflow(텐서플로우)에 내장되어 있는 유저친화적 API (수업에서는 2.x버전으로 사용).
딥러닝을 처음 공부할 때 Tensorflow + Keras 만한 프레임워크가 없다.
연구단 쪽에서는 Pytorch
현업에서는 Tensorflow를 주로 쓴다고 한다.
근데 둘 다 공부해야함 (일단 수업에서는 텐서플로우 ㅋ)
두 가지의 방식으로 모델링(코딩) 가능
- Sequential API : 내가 만들고 싶은 layer를 차례대로 차곡차곡 쌓으며 모델링
- Functional API : 내가 원하는 layer의 조합대로 연결해서 모델링
1. 선형회귀
선형회귀를 뉴럴 네트워크의 구조로 이해해보면 다음과 같다.

- 노드(Node) : 각 x와 y의 동그라미들은 노드라고 한다.
- Input layer : x노드들이 있는 계층
- Output layer : y노드가 있는 계층
- w : 각 x(feature) 변수에 대한 가중치
- 인풋 노드들은 아웃풋 노드로 Densely하게 연결되어있다.
[ 모델링 - Sequential API 방식 ]
- tensorflow + keras 불러오기
# 라이브러리 불러오기
import tensorflow as tf
from tensorflow import keras # 텐서플로우 2.x 버전에 내장된 케라스
import numpy as np
- 간단한 선형회귀를 위한 데이터(x,y) 생성
- feature의 개수를 확인하기 위해 x와 y의 shape를 체크해주는 것이 좋다.
x = np.array(range(0,20))
y = x * 2 -1
print(x)
print(y)
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
# [-1 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37]
# x와 y의 shape 확인
x.shape, y.shape
# ((20,), (20,)) -> 인풋과 아웃풋 각각 1개의 feature, 20개의 데이터 있음
[ 모델링 ]
Sequential API 방식의 모델링은 크게 4가지 과정을 수행해준다.
모델의 학습 이전까지 모델의 구조를 짜주는 과정
- 세션 클리어 : 이미 만들어진 모델이 있다면 모델을 없애주고, 메모리 효율도 높여준다.
- 모델 선언 : 레이어 블록을 쌓을 발판 생성
- 모델 레이어 쌓기 : model.add()로 레이어를 순서대로 쌓아준다.
- 컴파일 : model.compile()
## 모델링 : 선형회귀 -> Sequential API
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 모델 선언
model = keras.models.Sequential()
# 3. 모델 레이어 쌓기
model.add(keras.layers.Input(shape=(1,))) # Input layer -> Input feature가 1개
model.add(keras.layers.Dense(1)) # Output layer -> Output feature가 1개
# 4. 컴파일
# loss : 만든 모델의 예측값과 실제값을 비교할 평가지표
# optimizer : 경사하강법을 어떻게 진행할지
model.compile(loss='mse', optimizer='adam')- 인풋 레이어 : Input(shape=(Input feature의 개수,))
- 아웃풋 레이어 : Dense(Output feature의 개수)
[ 모델 학습 ]
- model.fit( x, y, epochs= )
- epochs : 갖고 있는 학습 데이터를 학습시킬 횟수
# 모델 학습
model.fit(x, y, epochs=10, verbose=1)아래와 같이 학습이 진행된다.

- 모델 예측, 확인
- 앞의 5개 예측값을 y와 비교해보자
# 모델 예측
y_pred = model.predict(x).reshape(-1) # y_pred를 1차원 구조로 확인
print(y_pred[:5])
print(y)
# [ 0.00999843 -0.37510583 -0.7602101 -1.1453143 -1.5304186 ]
# [ 10 7 4 1 -2 -5 -8 -11 -14 -17 -20 -23 -26 -29 -32 -35 -38 -41 -44 -47]
[ 모델링 - Functional API 방식 ]
Functional API 방식의 경우 모델링 과정만 Sequential과 조금 차이가 있다.
Sequential의 경우 레이어를 쌓을 때 그냥 순서대로 레이어를 model.add()로 추가해주었지만
Functional의 경우 레이어를 변수명으로 선언해주고, 레이어를 직접 명시해서 연결해주어야 한다.
- 세션 클리어 : 이미 만들어진 모델이 있다면 모델을 없애주고, 메모리 효율도 높여준다.
- 각 레이어 연결 : 각 레이어를 변수로 선언해주고, 연결할 레이어를 직접 명시해준다.
- 모델의 시작과 끝 레이어 지정 : 모델을 선언하면서 시작 layer와 끝 layer를 지정해주어야 한다.
- 컴파일 : model.compile()
## 모델링 : 선형회귀 -> Functional API
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 각 레이어 선언 후 연결
il = keras.layers.Input(shape=(1,)) # Input layer
ol = keras.layers.Dense(1)(il) # Output layer -> 연결하려는 레이어를 직접 명시
# 3. 모델의 시작과 끝 레이어 지정
model = keras.models.Model(il, ol)
# 4. 컴파일
model.compile(loss = 'mse', optimizer = 'adam')다른 과정은 Sequential과 동일
2. 로지스틱회귀 (이진 분류)
이진 분류 문제를 풀 때는 결과가 0~1 사이의 확률값으로 나와주어야 한다.
그냥 선형회귀식을 사용하면 범위가 무한대이기 때문에 선형회귀의 결과를 0~1 사이의 값으로 축소시켜주는 작업이 필요한데, 이를 수행해주는 것이 시그모이드 함수이다.
로지스틱회귀를 뉴럴 네트워크의 구조로 이해해보면 다음과 같다.
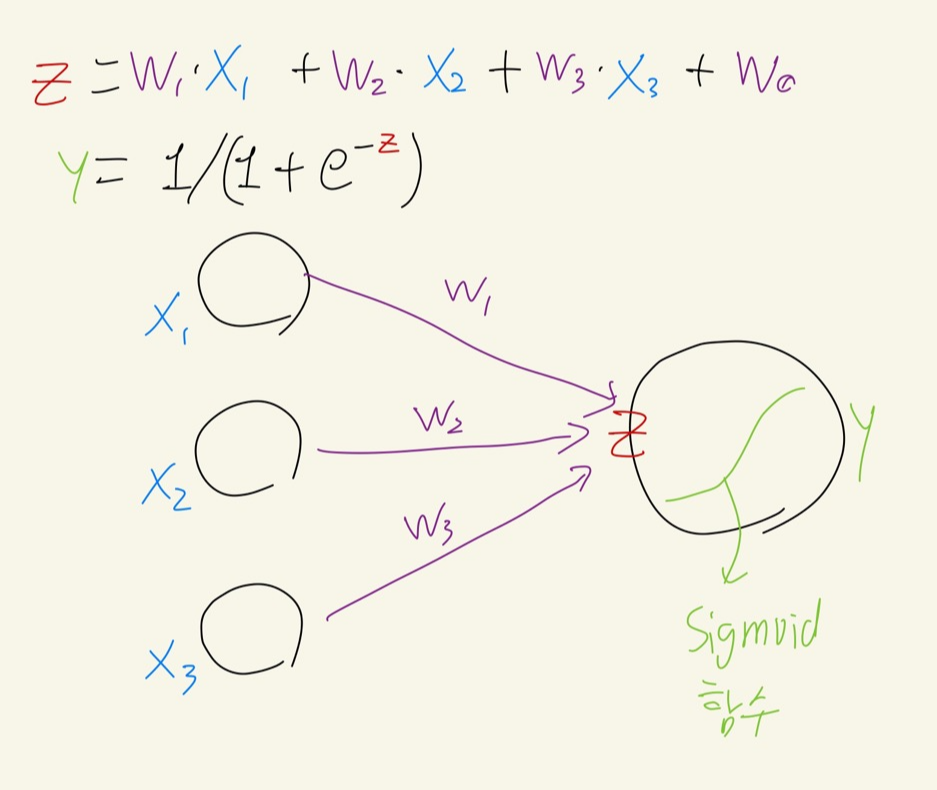
선형 회귀와 크게 다를 것은 없지만 Dense() 사용 시, Output feature의 개수와 활성화 함수로 시그모이드 함수를 지정해주어야 한다.
- 라이브러리 불러오기
import tensorflow as tf
from tensorflow import keras
import numpy as np
- 로지스틱회귀를 위한 데이터 생성
x = np.array(range(0,20))
y = np.array([0]*10 + [1]*10) # 이진분류를 위한 y값 생성
print(x)
print(y)
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
# [0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1]
# x와 y의 shape 확인
x.shape, y.shape
# ((20,), (20,))
[ 모델링 - Sequential API 방식 ]
- Dense()에 활성화함수로 시그모이드 지정 : activation='sigmoid'
- 컴파일 시 loss='binary_crossentropy' 사용
- 크로스엔트로피는 직관적으로 보기 어려운 지표이기 때문에 보조지표로서 metrics=['accuracy'] 옵션 추가
## 모델링 : 로지스틱회귀 -> Sequential API
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 모델 선언
model = keras.models.Sequential()
# 3. 모델 레이어 쌓기
model.add(keras.layers.Input(shape=(1,)))
model.add(keras.layers.Dense(1, activation='sigmoid')) # 시그모이드함수 적용
# 4. 컴파일
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
[ 모델링 - Functional API 방식 ]
## 모델링 : 로지스틱회귀 -> Functional API
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 각 레이어 선언 후 연결
il = keras.layers.Input(shape=(1,))
ol = keras.layers.Dense(1, activation='sigmoid')(il)
# 3. 모델의 시작과 끝 레이어 지정
model = keras.models.Model(il, ol)
# 4. 컴파일
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics=['accuracy'])
3. 멀티클래스 분류
사이킷런에서 제공되는 iris 데이터를 확인해보면 3개의 클래스를 분류하는 데이터이다.
데이터를 받아와서 확인해보면
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data
y = iris.target
x.shape, y.shape
((150, 4), (150,))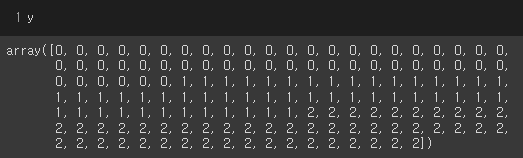
- Input feature는 4가지 feature( Sepal Length, Petal Length,Sepal Width, Petal Width )로 이루어져있고
- Output feature는 1개지만 0(setosa),1(versicolor),2(virginica)의 3개의 값을 갖는다.
output은 0,1,2의 값으로 Integer Encoding이 되어 있지만, 그렇다고 해서 0,1,2가 숫자적인 의미를 갖는 것은 아니다.
따라서 setosa, versicolor, virginica 각 클래스에 대한 결과를 각각 얻어내야 한다.
이를 위해 하나의 feature로 3개의 값을 갖는 것이 아니라, 각각의 클래스feature에 대해 0과1의 두가지 값만 갖도록 데이터의 구조를 바꿔주는 One-hot Encoding을 수행해준다.

뉴럴 네트워크 상에서 output으로는 각 클래스 별 결과를 0~1사이의 확률로 구해주고, 클래스 별 확률의 합이 1이 되도록 해주기 위해 소프트맥스(Softmax) 함수를 사용한다.
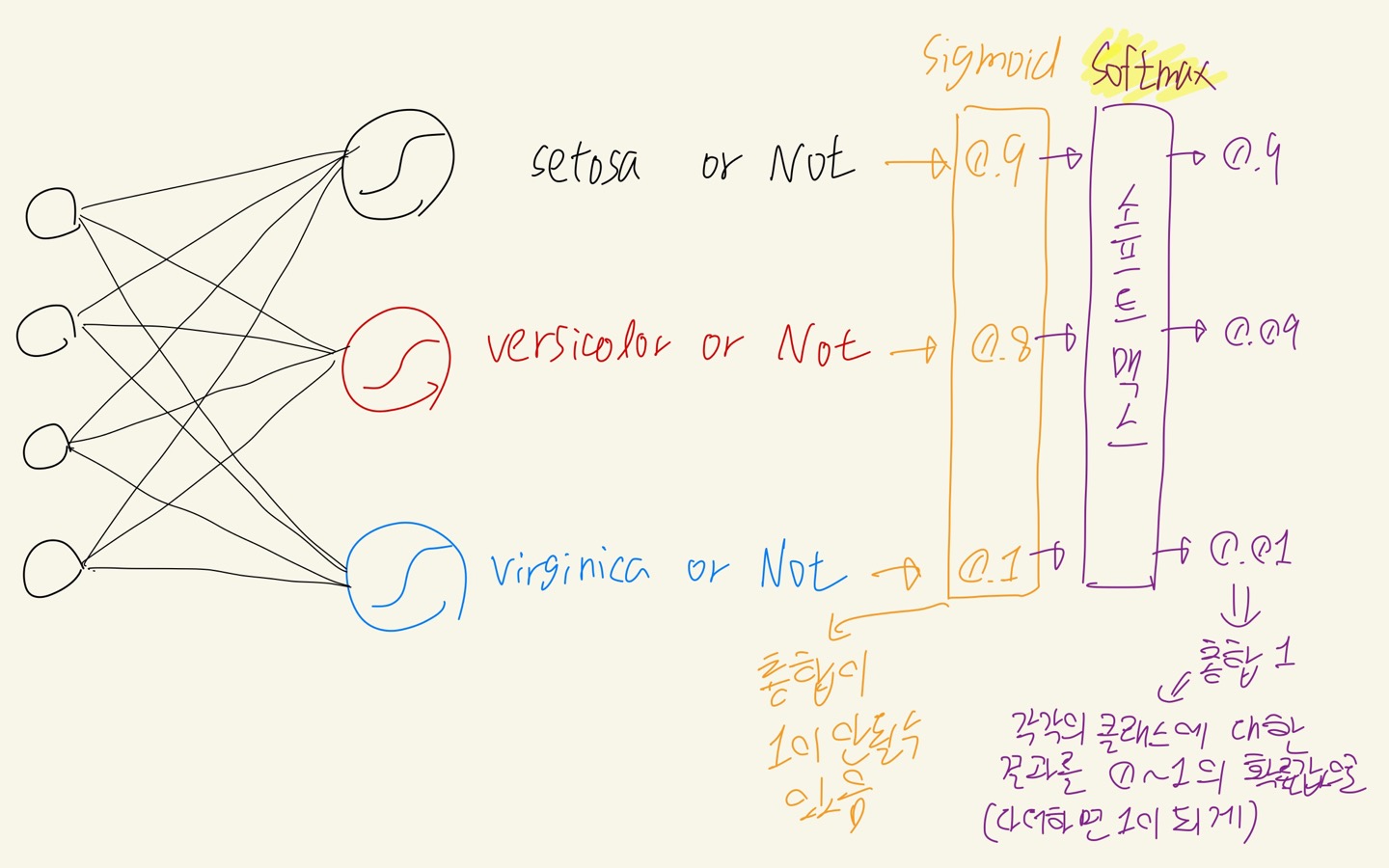
[ One-hot Encoding ]
tensorflow.keras.utils의 to_categorical() 함수를 사용해서 one-hot encoding을 해줄 수 있다.
from tensorflow.keras.utils import to_categorical
y = to_categorical(y, 3) # y를 3개의 카테고리로 (반복실행 주의)
# y의 feature가 3개로 됨
x.shape, y.shape
# ((150, 4), (150, 3))
[ 모델링 - Sequential API 방식 ]
- Dense()에 활성화함수로 소프트맥스 지정 : activation='softmax'
- 컴파일 시 loss='categorical_crossentropy' 사용
- 크로스엔트로피는 직관적으로 보기 어려운 지표이기 때문에 보조지표로서 metrics=['accuracy'] 옵션 추가
## 모델링 : 멀티클래스분류 -> Sequential API
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 모델 선언
model = keras.models.Sequential()
# 3. 모델 레이어 쌓기
model.add(keras.layers.Input(shape=(4,)))
model.add(keras.layers.Dense(3, activation='softmax')) # 소프트맥스함수 적용
# 4. 컴파일
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
[ 모델링 - Functional API 방식 ]
## 모델링 : 멀티클래스분류 -> Functional API
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 각 레이어 선언 후 연결
il = keras.layers.Input(shape=(4,))
ol = keras.layers.Dense(3, activation='softmax')(il)
# 3. 모델의 시작과 끝 레이어 지정
model = keras.models.Model(il,ol)
# 4. 컴파일
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
[ 학습 & 예측 & 결과확인 ]
예측결과는 각 클래스들에 대한 확률값의 리스트로 반환되기 때문에 가장 높은 확률을 갖는 클래스를 따로 확인해보려면 argmax()를 사용해주자.
# 학습
model.fit(x,y, epochs=100, verbose=1)
# 예측
pred = model.predict(x)
pred[:5]
# array([[0.7392779 , 0.21210867, 0.04861346],
# [0.6628284 , 0.2651919 , 0.07197971],
# [0.71210074, 0.22931857, 0.05858069],
# [0.6739107 , 0.2536423 , 0.07244709],
# [0.75563717, 0.19928277, 0.04508001]], dtype=float32)argmax()를 사용하면 행 기준(axis=1) 가장 큰 값의 인덱스를 반환하기 때문에 모델이 어떤 클래스로 분류했는지 바로 확인해볼 수 있다.
# 결과비교
print(pred.argmax(axis=1))
print(y.argmax(axis=1))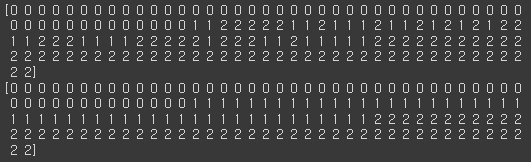
'KT AIVLE School' 카테고리의 다른 글
| (9주차 - 22.09.15) 딥러닝3 - 이미지(비정형)데이터 분류 (ANN 방식) (0) | 2022.09.16 |
|---|---|
| (9주차 - 22.09.14) 딥러닝2 - 히든레이어 (0) | 2022.09.15 |
| (7주차 - 22.09.05 ~ 22.09.06) AI모델 해석/평가 (0) | 2022.09.05 |
| (6주차 - 22.08.29) 머신러닝6 - 시계열 분석 (0) | 2022.08.29 |
| (5주차 - 22.08.26) 머신러닝5 - 비지도학습 (0) | 2022.08.26 |